늑대소년은 학교를 다니면서 축구라는 게임을 배웠습니다. 운동신경이 좋아서 체육 선생님이 골을 넣는 공격수를 시켰습니다. 늑대소년은 골을 넣는 것을 목표로 하고 그 목표를 달성하기 위해 자신의 행동을 끊임없이 수정해가며 노력했습니다. 처음에는 너무 세게 차서 공이 저 멀리 날아가기도 하고, 헛발질을 하는 경험도 합니다. 또 어떤 때는 골을 잘 넣기도 합니다. 그러한 과정을 여러 번 거치면서 ‘이렇게 하면 골이 잘 들어가는구나.’, ‘저렇게 하면 골이 잘 들어가지 않는구나.’ 라는 경험 데이터를 계속해서 쌓아갑니다. 학습은 이런 방식으로 계속 진행됩니다.
이 때, 늑대소년은 Agent(에이전트)입니다. 에이전트는 강화학습의 목표를 달성하기 위한 주체를 말합니다. 그리고 늑대소년이 골을 넣는 방법은 Environment(환경)이라 할 수 있습니다. 환경은 에이전트가 지금 당장 풀어야 할 문제입니다. 그리고 골을 차는 것을 Action(행동)이라고 합니다.
이해를 돕기 위해 늑대소년이 처음에는 세게 찼더니 공이 골대의 오른쪽으로 날아갔다고 생각해봅시다. 그러면 지금 당장 풀어야 할 문제 즉 Environment(환경)은 ‘지금보다 왼쪽으로 차라는 문제’로 바뀔 것입니다. 이렇게 바뀐 문제를 늑대소년 에이전트에게 알려주는 것을 State(상태변화)라고 합니다. 이러한 행동과 상태변화 과정이 여러 번 반복되다가 상태변화가 목표에 가까운 쪽으로 변화하면 에이전트인 늑대소년은 골대에 매달린 물을 마실 수 있습니다. 이 물을 Reward(보상)이라 합니다. 그러면 에이전트는 학습의 진행 방향을 파악하게 됩니다. 횟수가 반복 될수록 점점 목표에 근접한 Action(행동)을 할 수 있게 되는 것입니다. 늑대소년이 강화학습을 계속하게 되면 언젠가는 골을 매우 잘 넣어서 손흥민 선수와 같은 세계적인 축구선수가 될 수 있겠죠? 이렇듯 강화학습(목표지향학습, Reinforcement Learning)은 레이블(정답)을 제공하지 않고, 목표에 근접한 행동을 했을 때 보상을 제공합니다. 그렇기에 인과관계가 매우 중요하고, 스스로 했던 경험데이터를 기반으로 학습이 이루어집니다.
2. Q-Learning 알고리즘
Q-Learning 알고리즘은 강화학습 알고리즘의 대표적인 예입니다. 그러므로 Q-Learning을 시작하기전에 앞서 설명한 개념들을 가지고 강화학습의 의미를 짚어봅시다. 강화학습은 에이전트가 자신이 놓여있는 환경을 탐색하면서 보상을 받기 위한 행동을 하여 상태변화를 가져옵니다. 그리고 결국 그 보상이 최대화가 되었을 때의 행동을 찾아냅니다. 그것이 강화학습의 목표입니다.
Q-Learning 알고리즘에서는 에이전트가 현재의 상태에서 어떤 행동을 해야 미래에 가장 큰 보상을 받을 수 있는지 판단하는 것입니다. 그리고 그 판단은 모든 행동의 최대 효율값이 최대가 될 때 마다 새롭게 업데이트 되어 최대가 되는 값으로 행동을 수정합니다.
이 설명을 지금은 이해가 안될 수 있습니다. 하지만 아래에 있는 내용들을 충분히 공부한 뒤에 다시 이 굵은 글씨의 Q-Learning 알고리즘의 의미를 다시 읽어 봅시다.
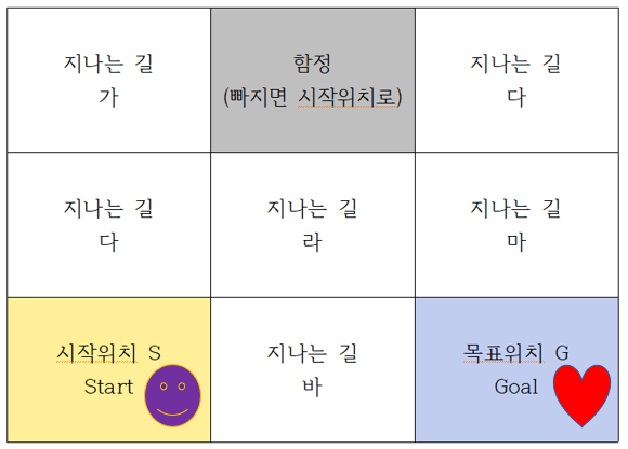
지금부터 게임을 생각해보겠습니다. 1. 게임의 목표 : 보라색 에이전트는 움직여서 목표위치에 도착하여 16점짜리 하트를 받아라
2. 게임의 조건
1) 에이전트가 지나는 길은 가~사까지 있으며 어느길을 가더라도 상관없다.
2) 지났던 길을 다시 지나가도 된다.
3) 가장 빨리 가는 길을 찾는 것이 제일 좋다.
4) 함정에 빠지거나 길을 못찾으면 시작위치S로 순간이동하여 처음부터 다시 시작한다.
여기까지만 게임설명을 해도 여러분은 가장 빠른 길을 찾아 에이전트가 하트를 받도록 할 수 있을 것입니다. 바로 S-사-G 의 길을 찾을 수 있는 것이죠. 너무 쉽게 찾습니다. 왜 쉽게 찾을 수 있었을까요? 네 그것은 바로 모든 것을 볼 수 있어서 시작 위치와 목표위치가 일직선상에 있다는 것을 알고 있기 때문일 것입니다.
그런데 만약 여러분이 에이전트이고 주변은 아주 캄캄한 밤이라고 생각해봅시다. 내가 이전에 가본적도 없고, 어떻게 생겼는지도 모르는 캄캄한 미로속에서 하트를 찾아야 합니다. 물론 하트도 빛은 없고 직접 그 앞에 가서 만져봐야 하트인지 알 수 있습니다. 그러면 여러분은 목표를 도달하기 위해 일단 움직일 것입니다. 하지만 어디로 갈지 모르기때문에 일단 어디로든 움직이는 것이죠. 단지 할 수 있는 것이라곤 헨젤과 그래텔에 나오는 남매처럼 지나온길을 돌로 표시하는 것입니다. 여기서 다행인것은 하트찾는 것을 실패하거나 함정에 빠지면 다시 처음 위치로 순간이동하는 것입니다. 그렇게 에이전트가 랜덤으로 길을 찾는다고 생각해봅시다.
이제 에이전트는 start 지점에서 할 수 있는 행동은 동서남북으로 이동하는 것입니다. 이것을 행동(action)이라고 합니다. 그리고 현재의 서있는 위치를 상태(state)라고 합니다.
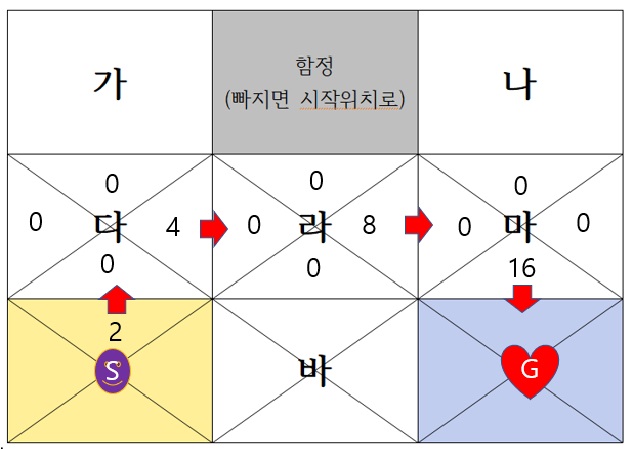
스마일 에이전트가 그 중에 에이전트가 처음 찾은 길이 S-다-라-마-G 라고 해봅시다. ‘마’위치 갈때까지 에이전트는 하트를 발견할 지 예상은 못했습니다. 너무 어두웠거든요 하지만 G에 도달했을 때 에이전트는 하트 16점을 받았습니다. 이것을 보상(reward)이라고 합니다. 그러면 에이전트는 이제 기억을 합니다. ‘아하 마 위치에서 남쪽으로 행동하면 16점을 받는구나’라고 입력합니다. 이것을 Q-value(내가 행동을 함으로써 예상되는 보상값)라고 합니다.
여기서 질문을 해보겠습니다. 라의 동쪽, 다의 동쪽, start의 북쪽의 Q-value값을 모두 16점으로 설정한다면 무슨 일이 일어날까요? 에이전트는 더이상 모험을 하지 않고, 한번 만에 우연하게 찾은 목표로 도달하는 길(S-다-라-마-G)을 통해서만 하트를 찾을 것입니다. 하지만 우리 입장에서 보면 제일 빠른 S-바-G길을 못찾는 agent가 똑똑하지 못하다 생각됩니다. 그래서 에이전트에게 처음 찾은 길외에도 다른 길을 찾도록 모험하게 하기 위해 Q-value값을 변화시켜줍니다. 그림에서 보듯 라의 동쪽 Q-value 값은 8점, 다의 동쪽Q-value값은 4점 으로 줍니다. 그러면 시작지점에서 북쪽으로 가는 것은 그 규칙에 의해 Q-value값이 2점이 됩니다.
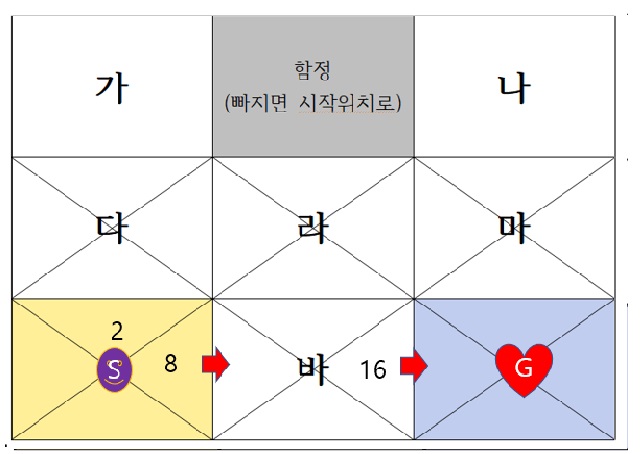
다시 에이전트를 랜덤으로 보내 새로운 길, 즉 더 좋은 길을 찾도록 모험을 하게 보냅시다. 그러다가 찾은 길은 S-바-G 입니다. 이제 같은 규칙에 의해 S의 동쪽 Q-value값을 계산해봅시다. Q-value값을 계산하는 규칙은 하트가 있는 목표지점을 기준으로 길을 하나씩 지날때마다 값이 절반으로 줄어드는 것입니다.
처음 S에서 동쪽으로 출발할때 보상에 대한 기대값은 0입니다. 왜냐하면 아직 하트를 찾을지 못찾을지 모르기 때문입니다. 바에 도착해서 동쪽으로 갈때에도 Q-value값은 0입니다. 하지만 G에 도착해서 16점을 받는 순간 에이전트는 이제 바의 동쪽 위치에 대한 Q-value값을 16점이라고 적어놓고 기억할 것입니다. 이제 그쪽으로 가면 16점을 받을 수 있다는것을 알게 되었기 때문에 업데이트 된것입니다. 그리고 다시 S의 동쪽에 대한 Q-value값을 절반규칙에 의해 8점이라고 기억 업데이트를 합니다.
이제 목표에 도달하는 두 개의 길을 찾았습니다. 그리고 출발뱡향에 대한 두 개의 Q-value값이 업데이트 되었습니다. 그러면 에이전트는 이제부터 출발지점에서 행동을 할 때 가장빠른 길을 찾으려면 Q-value값이 가장 큰 동쪽방향으로 움직이는 행동을 취하는 것이 좋다는 결론에 도달하게 됩니다.
지금까지 Q-learning에 대해 설명한 내용은 많이 축약되고 이해하기 쉬운 것을 골라 설명을 하였습니다. 하지만 그 이해에 대한 수학식이 때로는 더 쉬울 수도 있습니다. 여러분이 좀더 자세히 공부해보고 싶다면 Q-learnging에 관한 수식을 공부하는 방법도 추천합니다.
Q(s, a) = reward +Max Q(s’, a’)
a= argmax(Q(s, a) + random_value)
Q(s, a) = gamma * reward + Max Q(s’, a’), # 0 < gamma < 1