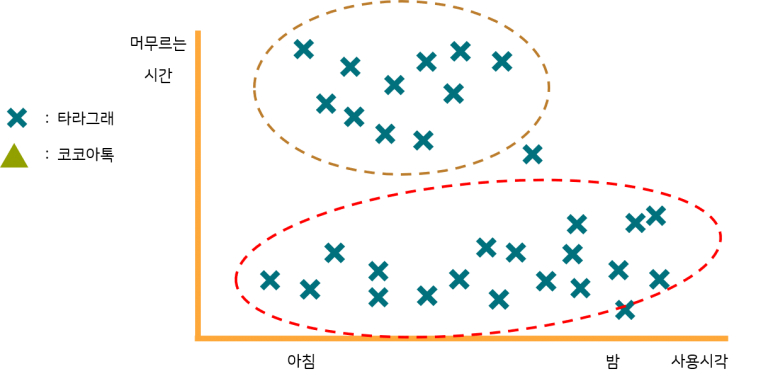
데이터는 생각보다 많은 이야기를 담고 있습니다. 아래는 두 메신저의 주 접속시간대와 사용자가 머무르는 시간을 나타내는 그래프입니다. 두 메신저의 사용자를 각각 분류해볼까요? 어떻게 나눌 수 있을까요?
어때요? 생각이랑 비슷한가요?
그럼 이렇게 생각해봅시다. 위의 것들을 그룹1이라고 하고 아래를 그룹2라고 해 봅시다.
두 메신저의 사용 용도는 어떤 것일까요? 추측해봅시다.
추측컨대 그룹1은 주로 업무시간대에 사용이 몰려 있는 것으로 보아 업무용 메신저일 것입니다. 밤에는 사용자가 낮보다 현저히 적네요. 이제부터 그룹1은 [타라그래] 메신저로 명명하죠. 그룹2는 아침부터 저녁까지 꾸준히 사용되고, 저녁시간대에 조금 더 쓰는 모습입니다. 일반사용자가 친목이나 대화를 위해 사용하는 메신저로 보입니다. 이제부터 이건 코코아톡이라고 하죠. 어때요, 추측이 그럴싸 한가요? 이렇게 가까운 데이터들을 분류해보는 일을 군집화(Clustering)이라고 합니다. 아래처럼 바꿔볼 수 있습니다.
2. K-Means 알고리즘
이제 K-Means 알고리즘을 알아보도록 합시다. 먼저 K-Means에서 K와 Means의 뜻은 무엇일까요? K는 중심점의 개수입니다. 즉 몇 개로 나눌 것인지 알아보는 것이죠. Means는 평균, 중심이라는 뜻입니다. 즉 이를 합쳐보면 K를 중심(means)으로 모이는 것을 의미합니다.
어떻게 이뤄지는지 하나씩 살펴볼까요? 다시 한번 데이터를 시각화(visualization)을 통해 2차원 그래프로 나타내봅시다.
앞의 타라그래와 코코아톡의 사용자를 조금 줄여보았습니다. 이제 여기서 K가 2인 K-Means를 실행해보겠습니다.
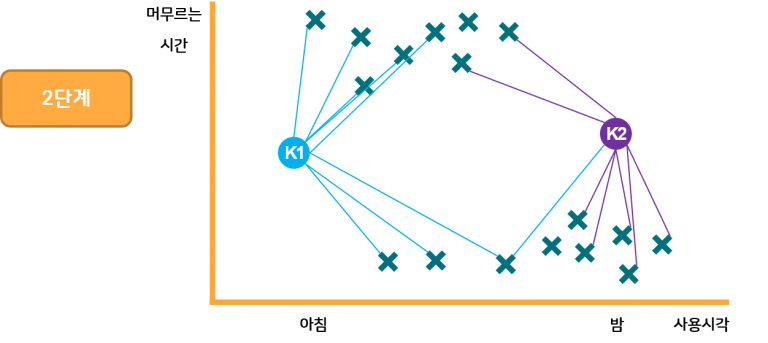
1단계에서 K는 기본적으로 무작위로 위치를 정합니다.
그리고 각 데이터를 가까운 K점에 연결합니다. 이를 Expectation 이라고 합니다.
각 거리의 합을 구해봅니다(제곱의 합). 그리고 합이 나오면 계산을 수행하여 거리들의 합이 가장 작은 방향으로 K 값을 이동합니다. 이 과정을 Maximazation이라고 합니다.
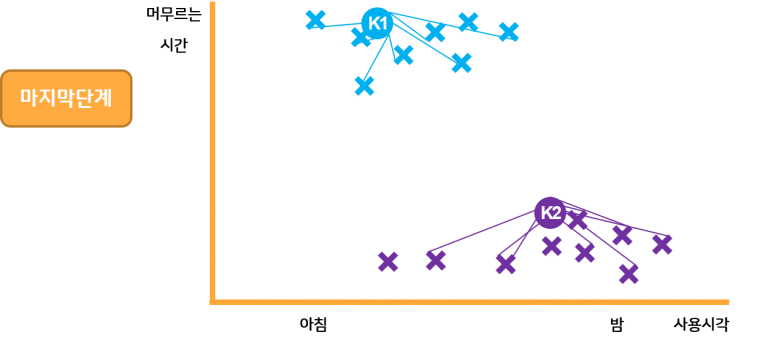
이를 계속 반복합니다. 그럼 더 이상 값이 작아지지 않아 K이 움직이지 않을때까지 반복하다가 멈추면 K의 최종 위치가 결정됩니다.
최종적으로 K의 위치와 이와 연결된 각 데이터들이 군집을 형성합니다.
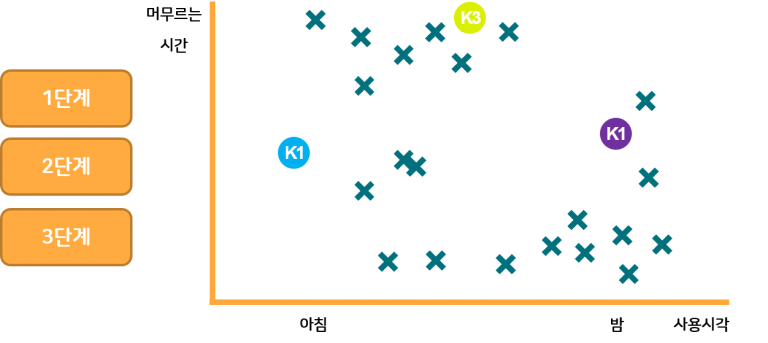
점이 세개일때도 마찬가지입니다. K-Means는 이렇게 쉬운 알고리즘과 간단한 계산으로 대규모 데이터에도 적용할 수 있는 장점이 있습니다. 또한 주어진 자료에 대한 정보가 많이 없더라도 군집화가 가능합니다.
K-Means는 알고리즘이 쉽고 간결하여 군집화(Clustering)에서 가장 많이 사용하는 알고리즘입니다. 그리고 대용량 데이터에서도 활용 가능합니다.
2. K-Means 알고리즘의 단점
K-Means의 단점은 데이터의 개수가 많을 경우 군집화의 정확도가 떨어집니다. 그리고 반복 횟수가 많아질수록 수행시간이 오래 걸리며, 몇 개의 군집으로 정하기가 어렵습니다. 자세히 알아봅시다.
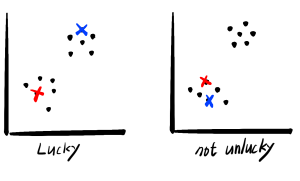
첫 번째로는 K의 초기 위치 선정입니다. 다음과 같은 경우를 보죠. K가 운좋게 잘 맞은 경우와 운이 좋지 않은 경우입니다. 첫번째의 경우 몇 단계 안에 계산이 끝나고 군집도 비교적 정확할 확률이 높습니다. 하지만 두번째 케이스의 경우에는 계산도 오래 걸릴 뿐더러 잘못 군집될 가능성이 있습니다.
이 경우에는 초기 K값을 무작위로 정하는 것이 아니라 K 위치를 정할 때 한번 무작위로 데이터를 선택하여 그 중심에 위치한 상태로 시작하기도 합니다.
또 데이터가 아주 많을 때, K의 개수를 직접 정해주어야 합니다. 컴퓨터가 알아서 K 값을 정해주지는 않는거죠.
어차피 어떤 데이터인지 모르는 상태에서 몇 개로 나눌 것인지 사람도 쉽게 정하지 못합니다.
마찬가지로 실제 군집이 4개인데 사용자가 3개로 인식하고 k를 3으로 설정하면 의미있는 데이터를 얻기 어렵습니다.
따라서 사람이 여러 번 실험을 하고, 이에 따라 결과값을 직접 해석하여 통찰력(insight)을 가지고 직접 알아내야 합니다.
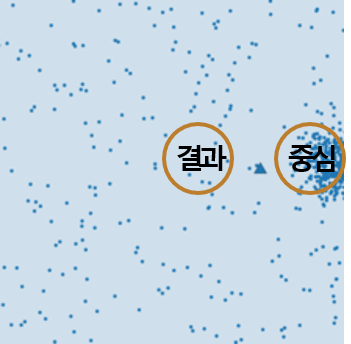
이 외에도 값들의 거리가 한쪽으로 쏠려있고 이상값(outlier)들이 멀리 떨어져있을 때 거리를 기준으로 계산하다 보니 실제 점이 오른쪽에 있기보다 왼쪽에 치우칠 가능성이 있습니다.