“하나를 보면 열을 안다.”는 인공지능에게도 적용되는 이야기일까요. 인간이 무언가를 알게 되는 과정은 명확합니다. 지나가는 개를 보고 옆에서 “저 강아지 귀엽지” 라고 하는 이야기를 들으면 저 동물이 강아지라는 것을 알게 되는 것이죠. 그럼 기계는 어떨까요. 인간과 같을까요?
2. 지도학습
1. 지도학습의 개념 쉽게 이해하기
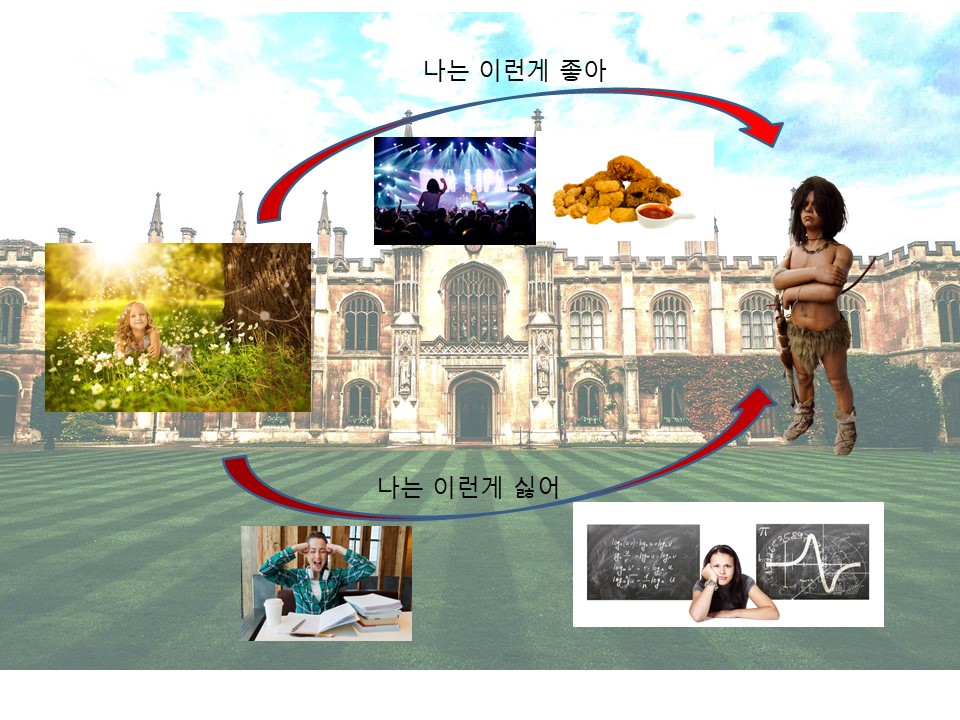
영희는 늑대소년을 인천으로 데려왔습니다. 그리고 경인초등학교에 입학을 시킵니다. 그리고 자신이 좋아하는 BTS, 치킨, 핸드폰을 알려주고 싫어하는 숙제, 책, 수학을 알려줍니다. 이렇게 미리 정답을 알려주며 학습시키는 것을 지도학습(Supervised Learning)이라고 합니다. 하나씩 하나씩 자신이 싫어하는 것과 좋아하는 것을 알려줄 때 이 정답을 레이블(Label)이라고 합니다. 기계는 각 레이블에 속하는 BTS, 치킨 같은 학습 데이터(Training Data)의 특징(Feature)을 파악합니다. 그리고 새로운 데이터(테스트 데이터, Test Data)가 어느 레이블에 속하는지를 판단합니다. 테스트 데이터가 어느 레이블에 속하는지 잘 구분할수록 기계의 정확도가 높다고 할 수 있습니다.
하지만 지도학습은 분명한 약점이 있습니다. 원래 가지고 있던 레이블에 속하지 않는 데이터나 새로운 속성을 가진 데이터가 있을 때 어느 레이블에 들어가야 할지 판단을 하지 못하는 경우가 생깁니다. 예를 들어 늑대소년이 치킨을 좋아하는 영희를 위해 새로 나온 매운 치킨을 가져다주었는데 영희는 매운 것이 싫다며 그 매운 치킨을 싫어한다고 가정해봅시다. 그러면 여기서 늑대소년이라는 기계는 판단하는 데 어려움을 겪습니다. 왜냐하면 치킨이라는 레이블은 좋아한다는 데이터를 가지고 있는데 새로 등장한 매운 치킨은 싫어하는 결과가 나왔기 때문이죠. 결국, 기존에 있던 치킨이라는 레이블 외에 매운 치킨이라는 새로운 레이블을 만들어 하나씩 정답인지 아닌지 알려주어야 합니다.
이것은 마치 영희가 늑대소년을 데리고 학교에 갔을 때 이제 좀 적응되었다 싶어서 혼자 잘 다닐 줄 알고 놀이공원을 데리고 갔더니 길을 잃는 것과 비슷한 상황입니다. 그러면 영희는 놀이공원에 있는 놀이기구부터 하나씩 설명하다가 지치게 될 것입니다. 이렇게 사람이 새로운 레이블이 생길 때마다 기계를 학습 시키면 효율도 떨어지고 그 데이터가 많을수록 시간도 오래 걸립니다.
2. 지도학습의 종류(분류와 회귀)
지도학습은 앞에서 설명했듯이 컴퓨터에게 문제와 답을 알려주며 가르치는 방법입니다. 컴퓨터는 문제(입력)와 답(출력)을 학습하여, 새로운 문제에 대한 답을 찾아내지요. 마치 우리가 문제집의 문제와 정답을 보며 공부하는 것처럼 말이에요. 이러한 지도학습의 종류는 새로운 답의 종류에 따라 분류(Classification)와 회귀(Regression)로 나눌 수 있습니다. 분류는 금방 이해가 될것 같은데 회귀라는 말이 조금 어렵죠?
분류(Classification)의 의미를 생각해봅시다. 분류는 찾아내고 싶은 답의 종류가 문자입니다. 예를 들어 고3 학생들의 공부 시간에 따라 대학교 합격과 불합격을 학습한 컴퓨터가 있다고 생각해봅시다. ‘공부를 만시간 하였으므로 A대학에 합격할 것이다.’ 라고 컴퓨터가 예상할 수 있습니다. 이것은 공부 시간에 따라 합격/불합격 여부를 예상하여 답을 내렸으므로, 이는 분류에 해당합니다.
회귀(Regression)의 의미를 생각해봅시다. 회귀는 찾아내고 싶은 답의 종류가 숫자입니다. 컴퓨터가 ‘공부를 만시간 하였으므로 수능점수 90점 받을 것이다’라고 숫자 값으로 답한다면, 이는 회귀에 해당합니다.
좀 더 자세히 알아봅시다.
①분류
출처: 픽사베이
분류(Classification)는 미리 배운 레이블(Label)을 바탕으로, 주어진 데이터가 어느 그룹에 속하는지 찾는 방법입니다. 앞서 우리가 다루었던 개와 고양이에 관한 예시는 분류의 대표적 사례라고 볼 수 있습니다. 수많은 개와 고양이 사진을 학습한 뒤, 주어진 사진이 개인지 고양이인지 확인하는 것이지요. 만약 개, 고양이, 토끼라는 3가지 레이블을 학습했다면, 컴퓨터는 주어진 데이터를 개, 고양이, 토끼 중에 가장 비슷한 레이블로 분류하게 됩니다. 개, 고양이, 토끼만 학습했기 때문에 코끼리 사진을 보여주더라도 세 가지 중에 가장 비슷한 것을 골라 대답하게 됩니다. 즉, 학습한 레이블 안에서만 답을 내릴 수 있으며, 코끼리라는 새로운 레이블이 갑자기 생기는 경우는 발생하지 않습니다.
그렇다면 컴퓨터는 어떤 원리로 분류 문제를 학습할까요? 먼저 ‘개’와 ‘고양이’로 분류된 각각의 데이터들의 특징(Feature)을 파악합니다. 그러다보면 개인지 고양이인지를 판가름할 수 있는 결정적인 특징들을 찾게 됩니다. 여러분은 어떤 특징이 떠오르나요? 꼬리의 길이일 수도 있고, 입이 튀어나온 정도일 수도 있습니다. 뒷다리나 귀의 모양일지도 모릅니다. 컴퓨터는 우리처럼 ‘꼬리’나 ‘귀’를 알아보지는 못하지만, 데이터를 분석함으로써 개인지 고양이인지를 결정할 수 있는 경계점을 찾습니다. 그리고 이에 근거하여 새로운 데이터가 개인지 고양이인지를 판가름합니다. 따라서 분류 문제의 정확도가 높아지려면, 학습된 데이터를 잘 분류할 수 있는 함수를 찾는 것이 중요합니다. 학습 데이터의 특징을 명확히 구분할 수 있는 함수일수록 새로운 데이터를 잘 구분할 가능성이 높겠죠?
이처럼 분류는 주어진 데이터에 대한 답을 학습한 레이블 중 하나로 정할 때 사용됩니다. 토끼와 사자의 중간, 0과 6의 중간과 같은 애매한 답을 내리는 것이 아니라, 더 가까운 레이블을 찾아 답으로 정합니다. 마치 보기는 5개이고, 답은 하나인 문제를 푸는 것과 같습니다. 정답이 3번인지 4번인지 헷갈리더라도 우리는 반드시 하나의 답을 정해야 합니다. 당연히 더 정답일 것 같은 보기를 고를 수밖에 없겠죠?
② 회귀
회귀(Regression)는 통계와 관련이 깊습니다. 1등급, 2등급, 3등급과 같이 정해진 몇 개의 레이블 안에서 대답을 정하는 게 아니라, 1.5, 4.2553, 2.6처럼 실수 범위 내에서 다양한 값을 답으로 출력할 수 있는 경우입니다.
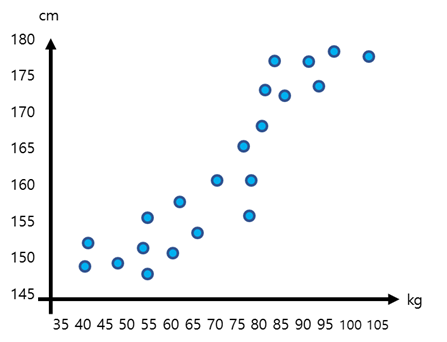
위 그래프는 학생들의 키와 체중을 조사한 내용입니다. 이 그래프에서 규칙을 찾을 수 있나요? 각 점들이 직선에서 너무 멀지 않도록, 점의 분포와 비슷한 위치에 직선을 그려봅시다. 빨간색 직선은 학생들의 키와 체중 데이터들의 경향성을 대표할 수 있는 직선입니다. 그렇다면 이 직선으로 조사하지 않은 학생들의 체중을 예상해볼 수 있습니다.
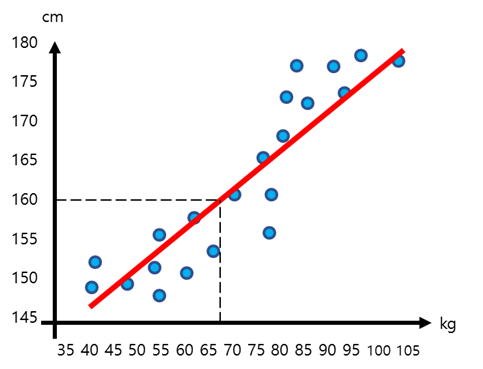
새로 그린 직선 그래프를 바탕으로 키가 160cm인 학생의 체중을 예상해봅시다. 위 그래프에 따르면 키가 160cm인 학생의 체중은 67.5kg일 것이라고 예상할 수 있습니다. 물론, 키가 160cm인 모든 학생의 체중이 67.5kg인 것은 아닙니다. 여기에서는 키와 체중만을 따졌고, 컴퓨터가 학습한 데이터의 양 역시 아주 적기 때문에 정확도는 당연히 떨어질 수밖에 없습니다. 이때 컴퓨터의 예측값과 실제값의 차이를 ‘오차’라고 합니다. 이 그래프는 아직 오차가 매우 크겠죠? 데이터를 더 많이 학습할수록, 더 다양한 데이터를 고려할수록 오차는 줄어듭니다. 따라서 회귀 문제에서는 오차를 줄이는 것이 중요한 과제입니다. 성별, 어린 시절의 비만 여부, 일주일 평균 운동량 등을 함께 고려한다면 더 정확한 예상이 가능합니다.
이상으로 지도학습에 대해 알아보았습니다.
다음 챕터에서는 비지도 학습에 대해서 자세히 알아보겠습니다.
Think Good AI
여러 데이터를 학습하여 분류를 하는 인공지능에게 학습시키는 사람의 생각에 따라 아래와 같이 편향되거나 잘못된 데이터가 들어갈 수 있다. 이로 인하여 생길 수 있는 문제점은 무엇일까?
– 여자는 머리가 길고 남자보다 열등한 반면, 남자는 머리가 짧고 여자보다 우월하다.
– 피부색에 따라 우월한 인종이 있다.
Ⅳ.자료와 학습 2.지도학습 QUIZ
지도학습의 종류는 크게 분류(Classification)와 회귀(Regression)가 있다. (O, X)
Correct!Wrong!
지도학습에 대해 알맞게 설명한 것을 모두 고르시요.
Please select 2 correct answers
Correct!Wrong!
컴퓨터에게 미리 정답을 알려주며 학습시키는 것을 지도학습(Supervised Learning)이라고 합니다. 이 정답을 레이블(Label)이라 합니다.(O, X)