현재 인공지능이 동작하는 방식 중 가장 널리 사용되고 있는 것은 기계학습입니다. 학습이란 말에서도 알 수 있듯이 인간이 아닌 기계가 학습하여 이를 지능으로 이용하고 있습니다. 그렇다면 대체 학습이란 무엇이고, 기계학습은 무엇일까요? 어떠한 방식으로 기계가 학습하고, 이것이 지능으로 이용될까요?
1. 기계학습의 정의
1. 기계학습(머신 러닝)의 정의
우리가 남긴 메시지, 촬영한 사진, 결제한 내용은 모두 자료, 즉 데이터(data)가 될 수 있습니다. 데이터는 조사와 연구의 바탕이 되는 재료로서 숫자나 문자뿐만 아니라 그림, 영상, 소리 등 다양한 형태로 존재합니다.
이러한 자료를 어떻게 정리하고 분석하느냐에 따라 우리는 다양한 정보(information)를 얻을 수 있습니다. 그리고 이렇게 얻은 정보는 사용자의 목적에 따라 다양한 분야에서 유용하게 활용될 수 있습니다. 예를 들어, 나이와 병원 지출 비용을 분석하여 20대보다 50대의 병원비가 더 많이 든다는 사실을 알아낼 수 있겠지요. 이 정보를 보험 회사에서 활용한다면 20대보다 50대에게 보험료를 더 많이 납부하도록 해야겠다는 결론에 도달할 수도 있을 것입니다. 다양한 자료와 정보가 넘쳐 흐르는 4차 산업혁명의 흐름 속에서 어떤 자료를 수집하고 분석할지, 그리고 그 결과를 어떻게 활용할지는 매우 중요한 논의가 될 수 있습니다.
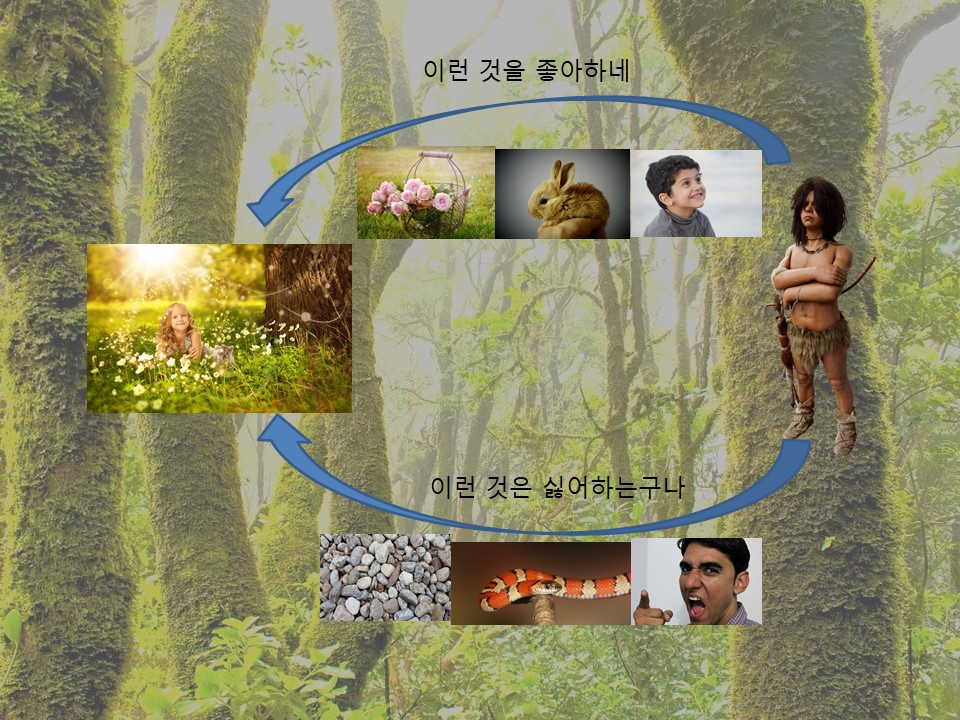
컴퓨터를 ‘늑대 소년’이라고 생각해봅시다. 이 소년이 태어나 자란 곳은 정글이고, 소년은 늑대무리와 살아왔기 때문에 사람의 말을 할 줄 모릅니다. 그러던 어느 날, 정글에 영희라는 친구가 길을 잃어 늑대소년과 만나게 됩니다. 늑대소년은 영희와 친해지고 싶었지만, 인간의 말을 할 줄 몰라 매일 선물을 가져다주기로 계획합니다. 첫째 날 소년은 영희에게 정글에서 위험한 동물들을 내쫓을 수 있는 돌멩이를 가져다주었지만 영희는 싫어합니다. 하지만 먹지도 못하고 쓸모없다고 생각했던 예쁜 꽃을 주니까 영희가 좋아합니다. 무더운 정글에서 목에 두르면 시원해지는 뱀을 가져다주니까 영희가 화들짝 놀라며 싫어합니다. 그리고 털이 많아 가지고 있으면 더워지는 예쁜 토끼를 주니까 영희가 좋아합니다. 자기가 소리치면서 말하면 영희는 인상을 찌푸리며 싫어하고 웃으면서 말하면 좋아하는 것을 알게 됩니다. 이렇게 매일 선물을 주면서 영희가 좋아하는 것들의 특징과 싫어하는 것들의 특징을 찾고 두 그룹으로 분류하면서 영희의 취향을 깨닫게 되었습니다.
이렇게 늑대소년인 컴퓨터가 다양한 데이터를 쌓으면서 경험을 계속해서 스스로 터득하는 것을 기계학습(머신러닝, Machine Learning)이라 합니다. 이는 기계가 스스로 공부한다는 뜻이 됩니다.
2. 기계학습(머신 러닝)의 유형
기계학습(머신러닝)의 유형에 대해 알아보겠습니다.
먼저 지도학습(감독학습, Supervised Learning), 비지도학습(Unsupervised Learning) , 강화학습(Reinforcement Learning)으로 나눌 수 있습니다. 필요에 따라 세 방법을 적절히 섞어서 사용하기도 합니다. 먼저 지도 학습은 문제와 답이 정해져 있는 자료들을 기계가 학습하는 방법입니다. 예를 들어 개와 고양이를 직접 보여주거나 사진을 주면서 ‘이것은 개’, ‘이것은 고양이’ 이렇게 답을 제시하면서 학습시키는 방법입니다.
다음 비지도 학습은 개와 고양이를 학습하지 않은 기계에게 개와 고양이 사진을 주면서 스스로 공부해보도록 하는 것입니다. 컴퓨터가 스스로 개와 고양이의 특징을 찾아 구별을 하도록 합니다. 답을 스스로 찾아야 하기 때문에 일반적으로 지도 학습보다 많은 데이터가 필요하고 결과값으로 사람이 원하지 않은 결과가 나올 수 있습니다.
마지막으로 강화 학습은 기계에게 목표를 알려주고 데이터를 통해서 결정할 때마다 그 결정에 대한 보상을 합니다. 목표에 가까운 결정일수록 높은 보상을 하면서 사람이 원하는 방향으로 기계가 학습하도록 합니다.
3가지 학습에 대한 자세한 내용은 각각의 해당되는 내용의 챕터( Ⅳ.자료와 학습(초급) – 2. 지도학습, 3.비지도학습, Ⅳ.자료와 학습(중급) – 3. 강화학습)에서 확인해보겠습니다.
3. 자료과학의 개념과 종류
컴퓨터가 학습하는 자료는 어떤 것이 있을까요? 사람들이 남긴 메시지, 촬영한 사진, 결제한 내용은 모두 자료(데이터, data)가 됩니다. 데이터는 조사와 연구의 바탕이 되는 재료로서 숫자나 문자뿐만 아니라 그림, 영상, 소리 등 다양한 형태로 존재합니다.
이러한 자료를 어떻게 정리하고 분석하느냐에 따라 우리는 유의미한 정보(information)를 만들 수 있습니다. 그리고 이렇게 얻은 정보는 사용자의 목적에 따라 다양한 분야에서 활용됩니다. 예를 들어, 나이와 병원 지출 비용을 분석하여 20대보다 50대의 병원비가 더 많이 든다는 사실을 알아낼 수 있겠지요. 이 정보를 보험 회사에서 활용한다면 20대보다 50대에게 보험료를 더 많이 납부하도록 해야겠다는 결론에 도달하여 보험료 책정에 반영할 것입니다. 그리고 소비자 입장에서는 자신의 수입을 고려해 적정한 나이대에 보험을 드는 것을 고려해 볼 것입니다.
현대 시대에서 자료는 넘쳐나지만 나에게 중요한 정보는 알기란 쉽지 않습니다. 어떤 자료를 수집하고 어떻게 분석할지, 그리고 그 결과를 어디에 활용할지 아는 것이 중요한 능력이 됩니다. 그러한 능력을 키우려면 우선 자료의 종류 부터 알아야 하겠습니다.
자료(data)는 그 형태와 연산 가능 여부에 따라 크게 정형 데이터, 비정형 데이터, 그리고 반정형 데이터로 분류할 수 있습니다. 데이터를 이와 같이 분류하는 상위 기준은 형태(schema)의 유무이며, 형태가 있는 데이터의 경우 그 하위 기준은 연산 가능(calculable) 여부입니다.
① 정형 데이터(Structured Data)
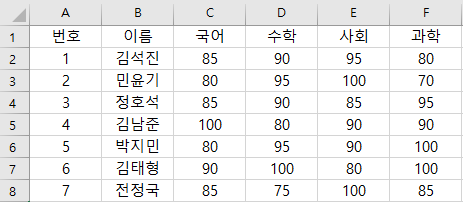
형태가 있고, 연산이 가능한 데이터를 정형 데이터라고 합니다. 키(key)와 값(value)을 테이블화한 관계형 데이터베이스(RDB)는 정형 데이터의 대표적인 예시입니다. 위 사진처럼 다양한 데이터가 주어져 있고, 이 데이터로 연산이 가능하다면 정형 데이터라고 볼 수 있습니다. 우리가 흔히 접하는 스프레드시트나 CSV도 모두 정형 데이터에 포함됩니다.
② 비정형 데이터(Unstructured Data)
출처: 픽사베이
출처: 픽사베이
정형 데이터와는 달리 구조화된 형태가 없는 데이터를 비정형 데이터라고 합니다. 형태가 없기 때문에 당연히 연산도 불가능하겠죠? 동영상, 이미지, 음성, 텍스트 데이터는 모두 비정형 데이터에 해당됩니다. 인스타그램, 페이스북, 트위터와 같은 소셜 네트워크에서 얻을 수 있는 데이터들도 비정형 데이터에 해당되지요. 그 예로, 인스타그램에 다양한 종류의 동영상·이미지·텍스트 데이터가 업로드 될 수 있는 것을 들 수 있습니다.
③ 반정형 데이터(Semi Structured Data)
데이터 중에는 정형 데이터처럼 형태를 가지고 있긴 하지만 연산은 불가능한 데이터도 있습니다. 이를 반정형 데이터라고 합니다. 반정형 데이터는 행과 열의 구조를 가지지는 않지만 데이터 내부에 데이터 구조에 대한 메타 정보를 가지고 있다는 특징이 있습니다.
예를 들어, 도서관의 책을 분류하고 관리하는 규칙에 대해 생각해 봅시다. 도서 목록은 행과 열의 틀에 넣을 수 있는 정형 데이터입니다. 하지만 그 분류 규칙은 행과 열을 가지고 있지 않죠? 그러나 분명 나름의 형태와 규칙을 가지고 있는 데이터입니다. 다만 우리가 그 규칙을 파악할 수 있어야겠지요. 즉 반정형 데이터의 경우, 데이터가 가지고 있는 형태를 파악하는 것이 중요합니다. 이러한 반정형 데이터의 예시로는 HTML, XML, JSON, 로그 형태 등이 있습니다.
Think Good AI
인공지능이 아래와 같은 데이터를 학습하였을 때 일어날 수 있는 문제점은 무엇일까? 이에 대한 부작용을 줄이거나 없애기 위해서는 어떤 일을 해야 할까?
– 성별, 인종, 직업 등을 기준으로 사람을 차별적으로 나눈 데이터 – 개인의 질병 내역, 보험료, 주치의, 과거 병력 등 의료정보
Ⅳ.자료와 학습 1.기계학습의 정의 QUIZ
기계학습 방법의 세 가지 주요 범주를 모두 고르시오.
Please select 3 correct answers
Correct!Wrong!
지도학습, 비지도학습, 강화 학습을 섞어서 함께 사용하는 것은 불가능하다. (O, X)
Correct!Wrong!
기계학습과 비지도학습의 관계는 장미와 꽃의 관계이다.(O, X)
Correct!Wrong!
-기계학습은 지도학습과 비지도학습 그리고 강화학습으로 나눌 수 있다.
머신러닝은 컴퓨터가 다양한 데이터를 쌓으면서 경험을 계속해 스스로 터득하는 것이다. (O, X)
Correct!Wrong!
형태가 없는 데이터는 정형데이터이다.(O, X)
Correct!Wrong!
형태가 없는 데이터는 비정형데이터이다
반정형데이터는 행과 열에 따라 데이터가 구조화되어 있다.
Correct!Wrong!
행과 열에 따라 데이터가 구조화 되어 있는 것은 정형데이터입니다.
그리고 반정형데이터는 행과 열의 구조를 가지지는 않지만 데이터 내부에 데이터 구조에 대한 메타 정보를 가지고 있습니다.