요즘 AI 면접을 심심치 않게 뉴스에서 들을 수 있습니다. AI 면접은 면접관의 주관이 개입되지 않고 이미 기업에서 설정해 놓은 객관적인 데이터만으로 공정성 있는 객관적인 평가를 할 수 있다고 합니다. 그럼 인공지능은 어떻게 사람의 말을 알아들을 수 있을까요?
2. 자연어란 무엇인가요?
한국어와 영어처럼 사람이 태어날 때부터 일상적으로 사용하고 있는 언어를 자연어(Natural Language)라고 합니다. 프로그래밍 언어와 같이 목적 달성을 위해 인위적으로 만들어진 언어와 구별해 특정 집단이 모국어로 사용하는 자연발생적인 언어라고 할 수 있습니다.
자연어는 언어별로 고유한 특성이 있습니다. 이 때문에 언어마다 사용되는 자연어 처리 기술은 각기 다릅니다. 왜 그러는지 띄어쓰기를 예를 들어 알아볼까요? 예시를 들어 설명해보겠습니다.
● 한국어 : 나는 학생입니다.
● 영어 : I am a student.
● 중국어 : 我是学生。(Wǒ shì xuéshēng.)
● 일본어 : 私は学生です。(Watashi wa gakusei desu.)
보시다시피 한국어에서는 띄어쓰기는 존재하지만, [나(대명사)+는(조사)]에서 볼 수 있듯 대명사와 조사가 붙어있는 형태입니다. 그러나 영어는 모든 단어를 다 띄어쓰기합니다. 그러나 중국어와 일본어에는 띄어쓰기가 존재하지 않아 모두 붙여 씁니다. 이런 경우 영어를 제외한 3개 언어에는 문장이 구성 요소를 분리하는 기술이 필요하겠지요? 띄어쓰기를 파악하지 못한다면 인공지능이 ‘아버지가방에들어가신다.’를 ‘아버지 가방에 들어가신다.’로 이해할 수도 있으니 말이죠!
3. 자연어 처리란 무엇인가요?
우리가 시리(Siri)나 Alexa와 같은 음성 어시스턴트에게 평소 사용하는 언어로 말을 하면 음성 어시스턴트는 사람의 언어를 인식하여 말을 처리하게 됩니다. 이처럼 사람의 언어를 컴퓨터에게 이해시키기 위한 기술을 자연어 처리(NLP: Natural Language Processing)라고 합니다. 이 기술은 인간과 기계 사이의 상호작용을 다루는 인공지능의 한 분야입니다.
우리가 일상적으로 사용하는 자연어는 같은 의미의 문장도 여러 형태로 표현이 가능하고 말의 순서를 바꾸거나 생략되어도 사람들끼리의 일상적인 소통에 문제가 되지 않아 융통성이 있습니다. 이런 언어를 부드러운 언어(Soft Language)라고 합니다. 이와 반대로 의미를 해석할 수 있는 문법이 정의되어 있고 정해진 규칙에 따라 해석이 되는 파이썬, C와 같은 프로그래밍 언어는 딱딱한 언어(Hard Language)라고 합니다.
우리가 일상생활에서 쓰는 언어는 문법적이지 못한 경우가 많아 컴퓨터에게 자연어를 체계적으로 나타내기가 어렵습니다. 현재로서는 약 90% 정도의 자연어를 처리할 수 있다면 성능이 좋은 수준이라고 할 수 있다고 합니다.
자연어 처리는 음성 인식, 맞춤법 검사, 사용자의 감성 분석, 정보검색, 문서 자동 분류, 내용 요약, 질의 응답 시스템, 챗봇, 번역 등과 같이 다양하게 활용되고 있습니다. 이에 대해서는 다음 파트에서 자세히 다루도록 하겠습니다.
4. 자연어 처리는 어떻게 발전되어 왔을까요?
최초의 자연어 처리 기술은 1940년대에서 시작됩니다. 워렌 위버(Warren Weaver)와 도널드 부스(Donald Booth)는 1946년 ‘기계 번역’이라는 개념을 제안했습니다. 번역은 첫째, 단어 사전 구축하고 둘째, 1대 1로 단어를 대치시킨 후 셋째, 문법적으로 재배열을 하는 과정으로 이루어집니다. 예문을 보면 금방 이해할 수 있을 것입니다.
‘I go to school.’을 번역하기 위해 [(I, 나), (go, 가다), (to, ~로/에/쪽으로), (school, 학교)]가 있는 단어 사전을 구축해야 합니다. 각 단어를 한국어로 치환한 후 한국어의 어순에 맞도록 위치를 바꾸어주면 자연스럽게 번역할 수 있습니다.
냉전 시기 미국은 러시아 문서의 자동 번역을 위한 시스템 개발을 시도하였습니다. 미국 정부의 지원으로 1952년에 시작하여 1964년 GAT(Georgetown Automatic Translation)이 개발되었습니다. 소련어로 된 물리학 관련 문서를 영어로 번역하는 것을 목표하였으나 사람에 비해서는 번역의 질이 매우 떨어졌습니다. 언어학 이론을 전혀 사용하지 않고, 단어+약간의 숙어 처리를 하는 방식으로 번역기를 만들었습니다.
1960년대에 본격적인 자연어 처리 연구가 이루어졌는데, 데이터베이스와 연동하여 질의에 응답하는 시스템을 개발하였습니다. 프랑스의 CETA, 캐나다의 TAUM이 그때 개발된 시스템입니다. 하지만 이때의 기계 번역은 완벽하지 않았습니다. 당시 학자들은 인공지능이 문장을 ‘이해’하지 못해도 구조 분석과 단어 대치 등으로 외국어 번역이 가능할 것이라 생각했으나 실제로 그렇지 않았기 때문이지요. 이 때문에 학자들은 인공지능에게 대화하는 영역에 대한 지식이 필요하다는 것을 깨닫게 됩니다.
이전 파트에서 설명한 위노그라드 스키마 챌린지를 기억하시나요? 이 대회의 이름의 주인공인 테리 위노그라드(Terry Winograd)는 1971년 MIT 학위 논문으로 SHRDLU 시스템을 만듭니다. SHRDLU는 물리적 법칙과 같은 간단한 세상을 이해하고 있어 자연어 처리 영역에서 인간의 언어처리 방법과 추론 방법을 결합한 모형을 사용했다는 측면에서 큰 발전을 이루었습니다.
그러나 1980년대 이후 자연어 처리의 암흑기가 도래하는데, 고전적인 방법으로 자연어를 처리하는 것에 한계를 느끼게 됩니다. 이후 딥러닝이 이를 해결하였고 현재는 사람과 대화가 가능한 수준까지 이르게 됩니다. 사람 같은 모습을 한 로봇에 챗봇을 장착해 대화를 시도하기도 합니다. 인공지능 로봇 제조사 핸슨 로보틱스(Hanson Robotics)가 개발한 인공지능 로봇 ‘소피아’가 대표적인 예입니다.
글은 문장으로, 문장은 단어들로, 단어는 형태소로 이루어집니다. 자연어 처리는 거꾸로 단어를 이해하여 문장을 이해하고, 나아가 글 전체 내용을 파악하는 일이라 할 수 있습니다. 자연어 처리 과정을 살펴보면 자연어로 이루어진 문장을 입력받으면 형태소 분석, 구문 분석, 의미 분석, 화용 분석을 거치게 됩니다.
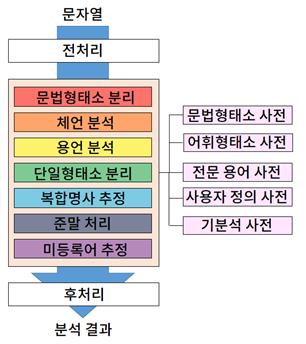
형태소 분석은 자연어 처리의 가장 기본적인 분석 작업으로 단어의 형태소를 인식하고, 불규칙한 활용, 축약, 탈락 현상이 일어난 경우 원형을 복원하는 작업을 의미합니다. 형태소 분석의 단계는 전처리, 문법형태소 분리, 체언 분석, 용언 분석, 단일형태소 분석, 복합명사 추정, 준말 처리, 미등록어 추정, 후처리의 과정으로 이루어집니다. 이 과정에서 문법형태소 사전, 어휘형태소 사전 등 여러 사전을 이용합니다.
형태소 분석의 단계(이건명, 2019)
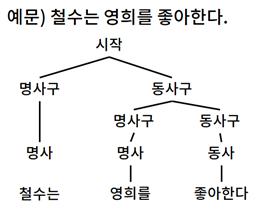
구문 분석(Parse)은 주어진 문장에서 단어들의 역할을 파악해 문장을 계층적인 트리 구조로 변환하는 일을 말합니다. 단어의 역할을 파악하는 것이 의미 이해에 매우 중요하므로 필수적인 작업입니다. 흔히 문장을 파싱(Parsing)한다고 표현하는데, 트리 형태로 만들어진 결과를 파스 트리(Parse tree)라고 합니다. 예문을 들어 설명해볼게요.
의미 분석은 앞 단계의 결과를 해석하여 문장의 의미를 파악하는 작업인데, 이를 위해 각각의 의미에 대한 지식 표현이 필요합니다. 자연어에는 같은 단어이지만 뜻이 다른 동음이의어가 많은데, 문장을 이해할 때 단어가 그 문장에서 어떤 의미로 쓰였는지를 파악해야 합니다. 특정 문장에 등장하는 단어가 어떤 의미인지 판별하는 작업을 ‘단어 의미 중의성 해소’라고 합니다. 예문들 들어 설명해볼게요.
화용 분석은 전체 문장에서 입력된 문장이 어떤 의미를 가지는지 분석하는 것을 말합니다. 이때 임의의 문장을 분석해야 하므로 매우 좋은 문법이 요구되는데, 고려해야 할 사항은 일반화(Generality, 다양한 문장을 분석), 구별성(Selectivity, 올바른 문장과 비문을 구별), 이해성(Understandability, 이해하기 쉽도록 간단)이 있습니다.
자연어 처리의 역사와 연결지어 봤을 때 자연어 처리 과정은 자연어 전처리로 1차 특징을 추출하는 데에는 효과적이었지만, 문장을 ‘이해’하는 것에는 한계가 있었습니다. 이에 대한 해결책으로 딥러닝이 도입되어 문장의 의미를 이해할 수 있는 돌파구를 마련하였습니다. 이를 기반으로 자동 번역, 음성 인식, 챗봇 등이 개발되었습니다. 다음 파트에서 자연어가 적용되는 분야에 대해 자세히 알아보도록 해요!
Think Good AI
인공지능을 이용하여 채용 면접을 본다고 가정해보자. 인공지능이 정한 결과를 신뢰할 수 있을까?
– 사람이 나쁜 의도를 가지고로봇을 이용하여 면접 결과를 조작할 경우
– 로봇이 잘못 인식하거나 오류를 일으킬 경우
참고 문헌 및 사이트
[인턴열전] “면접장서 심장박동까지 스캔당했다” AI면접 직접 봤더니 https://www.chosun.com/site/data/html_dir/2018/05/14/2018051401786.html