자연어를 컴퓨터가 처리하도록 하기 위해서 숫자로 바꾸는 방법을 알아야 합니다. 문자를 기계가 이해할 수 있는 숫자로 바꾼 결과 또는 그 과정을 임베딩(Embedding)이라고 합니다. 가장 간단한 형태의 임베딩은 문장에 어떤 단어가 많이 쓰였는지를 파악하여 글쓴이의 의도를 알 수 있습니다. 원-핫 인코딩(One-Hot Encoding)은 여러 기법 중 단어를 표현하는 가장 기본적인 표현 방법입니다.
원-핫 인코딩은 단어 집합의 크기를 벡터의 차원으로 하고, 표현하고 싶은 단어의 인덱스에 1의 값을 부여하고, 다른 인덱스에는 0을 부여하는 벡터 표현 방식입니다. 이렇게 표현된 벡터를 원-핫 벡터(One-Hot Vector)라고 합니다. 텍스트를 숫자로 표현하는 대표적인 방법으로 하나의 1과 수많은 0으로 표현하는 방법인데, 예문을 통해 이해해보도록 하겠습니다.
예를 들어, ”You say goodbye and I say hello.“라는 문서가 있을 때, “you”,”say”,”goodbye”,”and”,”i”,”hello”,”.” 라는 7개의 단어로 나뉠 수 있습니다.
이렇게 표현된 원-핫 벡터는 만약 단어가 20,000개라면 1개만 1이고, 19,999개의 0으로 표현되므로 희소 벡터*이고 벡터를 저장하기 위해 필요한 공간이 계속 늘어나므로 공간의 낭비가 발생하고 컴퓨터의 성능이 저하됩니다. 다른 말로 단어의 갯수만큼 차원 벡터가 만들어 진다고 표현할 수 있습니다.
또 다른 문제는 단어의 유사도를 표현하지 못한다는 것입니다. 사과, 복숭아, 레몬, 바나나라는 4개의 단어에 대해 원-핫 인코딩을 진행해 각각 [1, 0, 0, 0], [0, 1, 0, 0], [0, 0, 1, 0], [0, 0, 0, 1]이라는 원-핫 벡터를 생성했다고 하면, 사과와 복숭아가 유사하고, 레몬과 바나나가 유사하다는 것을 표현할 수 없습니다.
*희소 벡터(Sparse Vector) : 원소 대부분이 0인 벡터를 희소벡터라고 한다. 차원 감소의 핵심은 희소베터의 중요한 축을 찾아내어 더 적은 차원으로 다시 표현하는 것이다. 차원 감소의 결과로 원래 희소벡터의 원소 대부분이 0이 아닌 값으로 구성된 ‘밀집 벡터(Dense Vector)’로 변환된다.
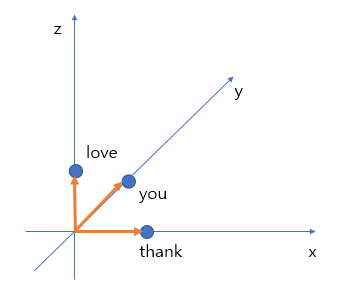
그림3-1 3차원
이해하기 편하게 만약 원핫표현을 단어 3개로 했다고 하면 3차원 벡터로 만들어 줍니다.
벡터로 표현한다는 것은 거리를 구할 수 있다는 것입니다. 그런데 원-핫 벡터는 단어 간의 유사도(거리를 이용하여 구할 수 있음)를 표현할 수 없습니다. 왜냐하면 보통 거리가 가까우면 단서가 서로 비슷하다고 판단하는데 원-핫 벡터를 사용하면 각각의 거리가 모두 같기 때문입니다.(그림 3-1 참고)
단어 간의 유사도를 알 수 없다는 것은 검색이나 추천 시스템에 문제가 됩니다. 예를 들어 대학교 입시를 위해 ‘경인교육대학교 입시’라는 단어를 검색한다고 했을 때, ‘경인교육대학교 합격 점수’, ‘경인교육대학교 초등교육과’, ‘경인교육대학교 입시 일정’ 등과 같은 유사 단어에 대한 결과도 함께 보여줄 수 있어야 합니다. 그러나 단어 간의 유사도를 알 수 없으면 이런 연관 검색어를 보여줄 수 없게 됩니다.
이러한 단점을 해결하기 위해 단어의 의미를 반영해 다차원 공간에 추론 기반으로 벡터화하는 기법인 Word2Vec에 대해 이어서 공부하도록 하겠습니다.
Word2Vec
통계 기반 기법으로 문장의 단어 빈도수를 기본으로 단어를 벡터로 표현하였습니다. 하지만 이 방식은 대규모 문서(말뭉치)를 다룰 때는 문제가 발생합니다. 반면 추론 기반 기법은 학습 데이터의 일부를 사용하여 순차적으로 학습합니다. 추론 기반 기법의 대표적인 것이 바로 Word2Vec입니다. Word2Vec은 뉴럴 네트워크 언어 모델(Neural Net Language Model, NNLM)을 기반으로 대량의 문서를 벡터 공간에 고 수준의 의미를 지닌 벡터를 가지도록 하는 모델이라고 할 수 있습니다.
단어의 의미는 주변 단어에 의해 형성된다고 봅니다. 단어 자체에는 의미가 없고, 사용된 ‘맥락’에 의미를 형성합니다. 맥락을 분석하기 위한 방법으로 윈도우 크기를 지정해 특정 단어와 그 주변에 발생하는 단어들을 함께 묶어서 분석하는 방법을 분포 가설이라고 합니다.
따라서 추론 기반 기법은 분포 가설에 기반하여 맥락을 이용해 중심 단어를 추론하는 작업이라고 할 수 있습니다.
Word2Vec에는 CBOW(Continuous Bag of Words)와 Skip-Gram 두 가지 방식이 있습니다.
① CBOW 모델은 주변 단어(Context Word)로부터 중심단어(Center Word)를 추측하는 신경망입니다.
문장에 빈칸을 두고 적절한 단어를 추론하기 위한 단어의 분산표현 정보가 만들어집니다. 어린 학생들이 언어를 배우는 과정과 비슷합니다.
(말뭉치에서 주변 단어와 중심 단어 작성하기)
(참고로 윈도우를 계속 움직여서 단어 선택을 바꿔가며 학습을 위한 데이터 셋을 만드는 것을
슬라이딩 윈도우(Sliding Window)라고 합니다.)
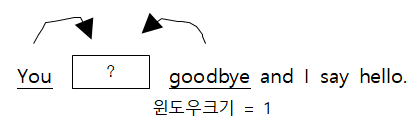
윈도우 크기가 1개 이면 주변 단어의 개수는 2개가 됩니다. 윈도우 크기가 2이면 주변 단어의 개수는 4가 됩니다. 그러므로 윈도우 크기가 n개이면 주변 단어의 개수는 2n이 될 수 있습니다.
(참고)윈도우 크기 : 중심 단어를 예측하기 위해서 앞 뒤로 몇 개의 단어를 볼지를 정했다면 그 갯수를 윈도우(window)라고 한다.
(단어ID 배열에서 주변단어와 중심단어 작성하기)
(원핫표현)
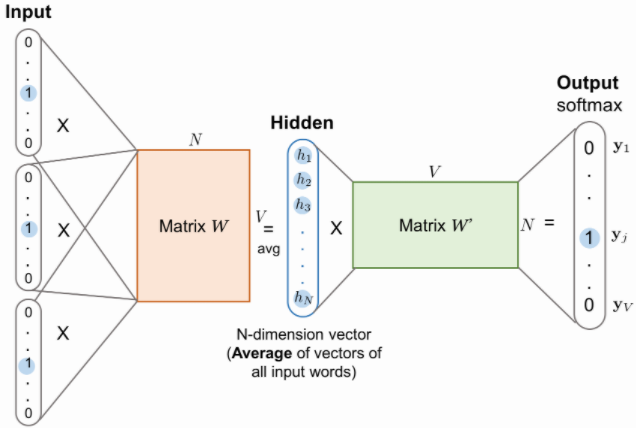
CBOW 모델을 도식화하여 나타내면 다음과 같습니다. 입력층(Input Layer)에는 앞, 뒤로 사용자가 정한 윈도우 크기 범위 안의 주변 단어들이 원-핫 벡터로 들어가게 되고, 출력층(Output Layer)에서 예측하고자 하는 중심단어의 원-핫 벡터가 필요합니다. 입력층과 출력층 사이에는 하나의 은닉층(Hidden layer)이 존재하는 것을 알 수 있습니다. Word2Vec의 은닉층에는 다른 일반적인 것들과는 달리 활성화 함수가 존재하지 않고 룩업 테이블이라는 연산을 담당하는 층이기 때문에 일반적인 은닉층과 구분하기 위해 투사층(Projection Layer)이라고 부르기도 합니다.
CBOW 모델을 도식화하면 다음과 같습니다.
CBOW모델
② Skip-Gram 모델은 중심단어로부터 주변 단어를 추측하는 신경망입니다.
하나의 단어를 주고 문장에 들어가는 나머지 단어들을 추론하기 위한 분산표현 정보가 만들어집니다. 학생들이 작문을 통해 언어의 실력을 높여가는 과정과 비슷합니다.
Skip-Gram 모델을 도식화하면 다음과 같이 표현할 수 있습니다.
Skip-Gram모델
학습시간은 CBOW 모델이 빠르지만 학습 대상 말뭉치가 커질수록 Skip-Gram 모델이 더 뛰어난 성능을 발휘합니다. 그래서 skip-gram 모델의 성능이 더 뛰어나다고 할 수 있습니다.
통계기반 기법에서는 유사성만이 표현되는 반면, 추론 기반 기법에서는 단어 사이의 패턴도 학습이 됩니다.
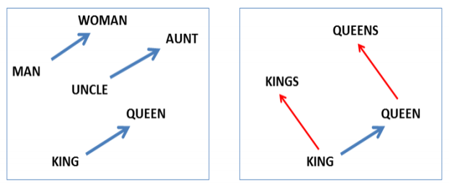
그림1
[그림1]은 word2vec을 사용하여 단어를 2차원 벡터로 변환한 예입니다. 위의 그림에서 ‘Man’과 ‘Woman’의 거리는 ‘King’과 ‘Queen’의 거리와 비슷한 것을 알 수 있습니다. 이처럼 학습을 통해 단어의 문맥적 의미를 수치적으로 보존하기 때문에 이를 이용하여 각 단어들 간의 유사도를 측정하거나 수치적으로 쉽게 다룰 수 있습니다.
한국어 Word2Vec http://w.elnn.kr
위 사이트에서는 단어들(Word2Vec 벡터)로 덧셈과 뺄셈을 할 수 있습니다. 위에 있는 사진처럼 한국-서울+도쿄를 넣으면 일본이 나오는 것처럼 ‘김연아-피겨+야구’를 입력하면 ‘박찬호’가 출력됩니다. 다양한 단어들을 입력하여 어떤 결과가 나오는지 확인해보세요!
Word2Vec 모델은 자연어 처리에서 단어를 밀집 벡터로 만들어주는 단어 임베딩 방법론이지만 추천 시스템에도 사용되고 있는 모델입니다. 위치가 근접할수록 유사도가 높은 벡터이기 때문입니다. 노래를 추천해주는 Spotify나 방송을 추천해주는 아프리카TV에서도 사용된다고 합니다.
참고 자료 및 사이트
Elements of AI (https://www.elementsofai.com/)
Won Joon Yoo, Introduction to Deep Learning for Natural Language Processing, Wikidocs