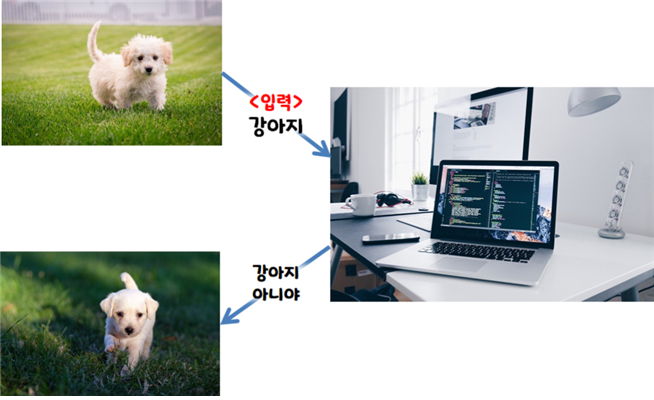
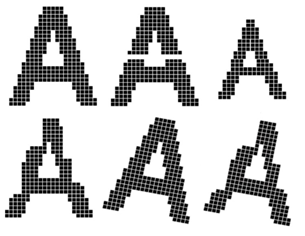얼굴 인식 인공지능을 만들기 위해서는 얼굴을 구별할 수 있도록 해 주는 알고리즘이 필요합니다. 여러분이 어떤 사람을 구별할 때 사용하는 전략을 생각해 봅시다. 사람마다 키와 몸무게, 생김새, 피부색, 지능, 성별 등 각자 지니고 있는 특징이 모두 다르지요. 여러분이 이 사람을 다른 사람과 구분할 때 이 모든 정보를 활용하나요? 아마 대강 살펴보고 이 사람에게서 보이는 대표적인 특징을 찾아낼 것입니다.
하지만 컴퓨터는 사람과 다르게 판단합니다. 강아지를 찍은 사진을 그냥 컴퓨터에게 입력하고 다른 강아지의 이미지를 입력하여 강아지인지 판별하도록 한다면 컴퓨터는 이 사진은 강아지가 아니라고 판단할 것입니다. 컴퓨터는 미리 입력된 이미지만 강아지라고 인식하기 때문입니다. 가지고 있는 데이터와 조금이라도 다른 점이 있으면 ‘다른 것’이라고 한다는 거죠. 정확하지만 융통성이 없습니다.
다음 그림을 봅시다. 무엇이 보이시나요?
어렵지 않게 A자 6개가 있다고 답할 수 있을것입니다. 그런데 컴퓨터는 6개를 다 다르게 인식합니다. 첫 번째 A를 학습시켰다면 두 번째 A는 중간에 끊어져 있기 때문에 다르게 인식합니다. 세 번째 A는 크기가 작습니다. 네 번째 A는 모양이 다르고 다섯 번째 A는 회전하였습니다. 여섯 번째 A는 모양과 방향이 학습시킨 A와 다릅니다. 그래서 컴퓨터는 A로 인식할 수 없습니다.
인공지능 개발자들은 이런 문제점을 해결하기 위해 CNN(Convolutional Neural Network)이라는 인공신경망을 개발하였습니다. 컴퓨터에게 이미지에서 특징적인 부분만을 골라내어 비교하여 완벽하게 동일하지 않더라도 비슷한 특징을 가지고 있다면 같은 종류일 가능성이 높다고 판단하는 것입니다.
CNN은 ‘합성곱 신경망’으로 옮기기도 합니다. 너무 어려운 개념이라 쉽게 비유해서 설명하겠습니다. CNN은 이미지를 간단하게 바꾸는 필터의 역할을 한다고 생각하면 됩니다. 필터는 카메라 렌즈에 끼워 사용하는 것이죠. 노란색 필터를 끼우면 사진도 노랗게 나오게 됩니다.
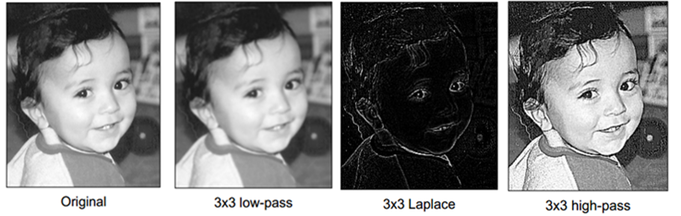
CNN은 이미지에서 필요한 부분만을 걸러내어 비교합니다. 이미지에는 색, 명암 등 너무 많은 정보가 담겨 있기 때문에 형태만을 비교하려고 하는 경우 아래 그림처럼 필터링 처리를 하게 됩니다. 필터의 특성에 따라 이미지의 저차원적 특성에서 고차원적인 특성을 도출하게 되고 이미지의 크기나 이동에는 영향을 받지 않는 고유의 특성을 얻을 수 있습니다.
https://blog.naver.com/laonple/220594258301
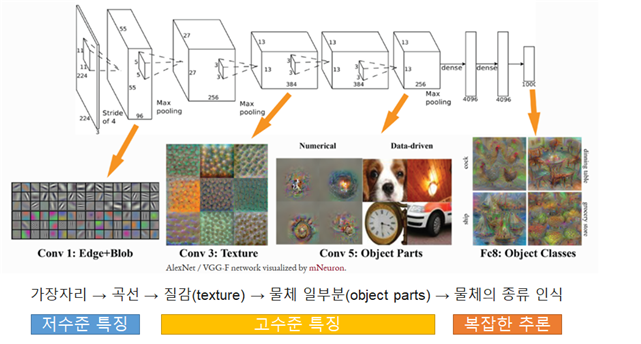
합성곱신경망은 물체의 특징점을 학습하므로 물체의 위치와 방향이 변해도 물체를 인식할 수 있습니다. 합성곱신경망은 컨볼루션계층, 풀링계층, 완전연결 계층으로 이루어집니다.
컨볼루션 계층에서는 입력데이터 중 다양한 위치에서 발견되는 동일한 특징을 추출합니다. 풀링계층에서는 각 특징 맵의 해상도를 줄여 데이터의 공간적인 크기를 축소하며 물체의 위치, 크기, 각도 변화에 대처하도록 합니다.
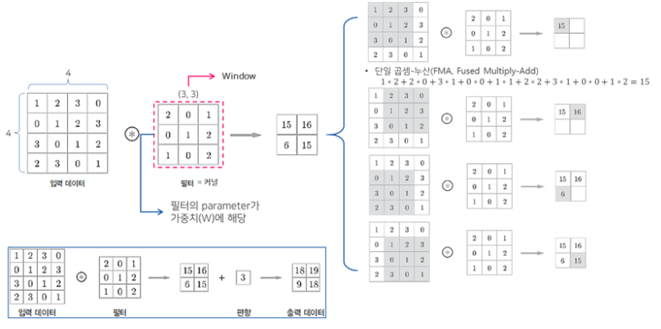
합성곱(convolution) 연산은 입력된 데이터와 필터를 사용하여 수행됩니다. 아래와 같이 합성곱을 수행한 결과 피쳐 맵을 생성할 수 있습니다. 입력되는 이미지의 데이터에 필터를 적용하여 얻어낸 출력 데이터는 크기가 작아지며 강한 특성들이 추출됩니다.