자연어를 처리하는 기법에는 여러 가지가 있습니다. 이번에 설명할 백오브워즈(BoW)와 TD-IDF는 통계 기반의 단어 표현(Count based word Representation)이 이에 해당합니다. 지금부터 자세히 살펴보도록 하겠습니다.
백오브워즈(Bag Of Words)
백오브워즈(Bag of Words)는 단어의 순서에 관계없이 문서 내 단어의 등장 빈도를 계산하는 방법입니다. 백오브워즈를 영어 그대로 해석해보면 ‘단어들의 가방’이듯이 문장에 있는 단어들을 가방에 넣고 흔들면 뒤죽박죽 섞여서 순서를 사용할 수 없게 되고 대신 단어가 출현한 빈도를 세어 무언가를 하게 되는 것입니다.
백오브워즈는 주제가 비슷한 문장이라면 단어 빈도 역시 비슷할 것이며 빈도수를 그대로 백오브워즈로 쓴다면 많이 쓰인 단어가 주제와 강한 관계가 있을 것이라는 전제가 깔려 있습니다. 예문을 통해 자세히 설명하도록 하겠습니다.
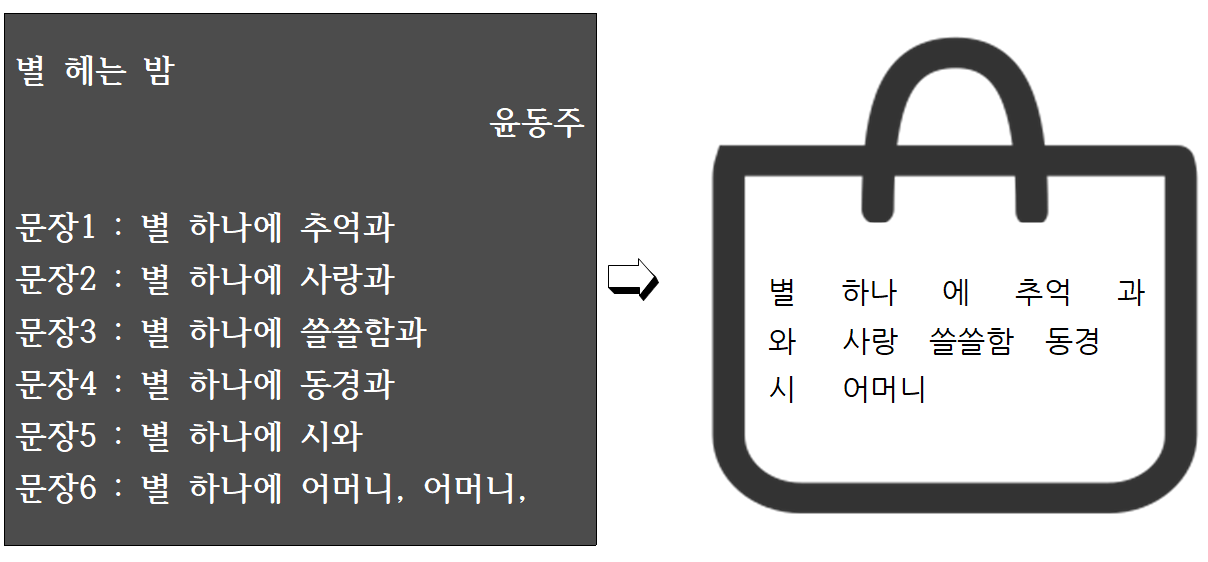
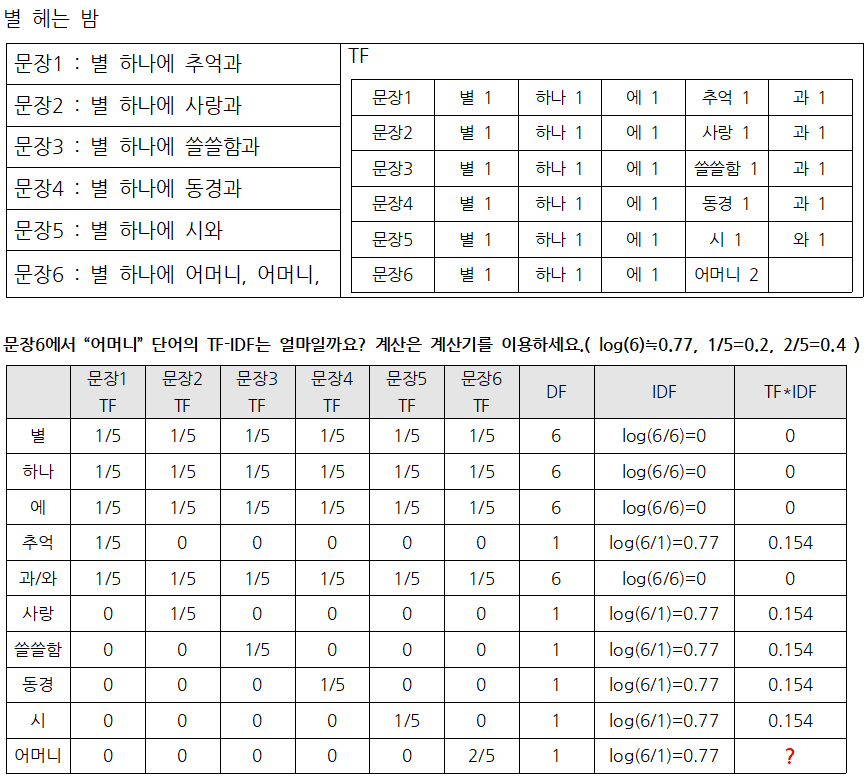
다음은 윤동주의 시 <별 헤는 밤> 입니다. 다음 시의 주제어를 백오브워즈 방식으로 찾아 봅시다.
시를 한 줄씩 문장으로 생각하여 의미가 있는 최소단위로 잘라서 오른쪽의 가방에 넣습니다.
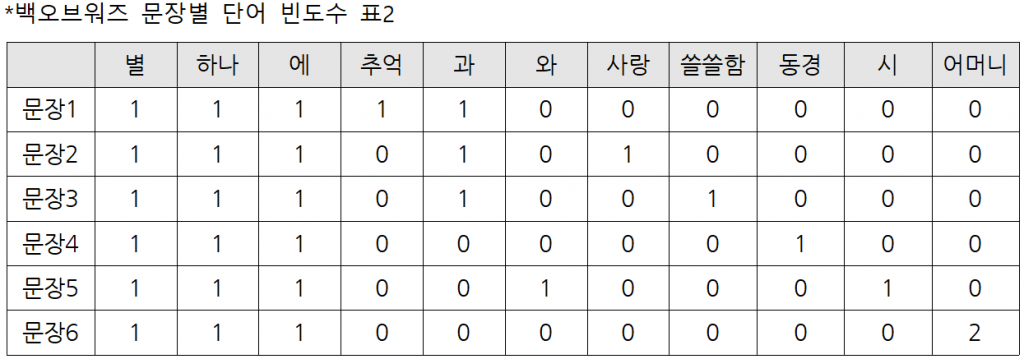
[표1]은 출현한 단어들의 목록이며 각 출현 횟수를 정리하였습니다.
[표2]는 문장별로 단어의 출현횟수를 정리한 표입니다.
(참고: 이렇게 표로 표현한 것을 문서 단어 행렬(Document-Term Matrix, DTM)이라고 합니다.)
백오브워즈는 각 단어가 등장한 횟수를 수치화하는 방법이기 때문에 어떤 단어가 얼마나 등장했냐를 기준으로 그 문서가 어떤 성격의 문서인지를 판단하는 작업에 사용됩니다. 다시 말해, 분류 문제나 여러 문서 간의 유사도를 구하는 문제에 쓰입니다. 예를 들어, ‘금리’, ‘물가상승률’, ‘GDP’등과 같은 단어가 자주 등장한다면 경제 관련 문서로 분류할 것이며, ‘미술관’, ‘화가’, ‘작품’과 같은 단어가 자주 나온다면 미술 관련 문서로 분류하겠지요?
백오브워즈의 문제는 단순 빈도로 접근하기 때문에 기본적으로 모든 단어에 동일한 중요성을 부여한다는 것입니다. ‘이/가’와 같은 조사가 10번 나오는 것은 ‘사랑’이라는 단어가 10번 나오는 것만큼 중요하게 되는 것이죠. 그러나 예를 들어 문장 안의 감정을 분석한다고 하면 ‘이/가’와 ‘사랑’이 똑같이 중요하다고 할 수 있을까요? ‘이/가’와 같은 불용어(Stopwords)는 자연어 처리에 있어 의미를 거의 갖지 못하기 때문에 ‘사랑’과 같은 중요한 단어에 대해 가중치를 줄 수 있는 방법이 필요하겠죠?
이런 백오브워즈의 문제점을 개선하기 위해 사용할 수 있는 좋은 방법은 이어서 설명할 TF-IDF입니다.
TF-IDF는 우리말로 ‘단어 빈도-역 문서 빈도’라고 합니다. 문서의 빈도에 특정 식을 사용해 여러 문장으로 이루어진 문서에서 어떤 단어가 특정 문장에서 얼마나 중요한 것인지를 나타낸 통계적 수치입니다. 문서의 키워드를 찾거나 검색엔진에서 검색 결과의 순위를 결정하거나, 문서들 사이의 비슷한 정도(유사도)를 구하는 용도로 사용할 수 있습니다.
TF-IDF는 TF 값과 IDF 값을 곱한 값을 의미하는데, 지금부터 하나하나 이해해보도록 합시다.
TF(단어빈도, Term Frequency)는 특정 단어가 문서에 얼마나 많이 사용되었는지 빈도를 나타냅니다. 많이 쓰인 단어가 중요하다는 가정을 전제로 한 수치입니다. TF값이 높으면 문장에서 중요한 단어가 됩니다. 예문을 통해 알아볼까요?
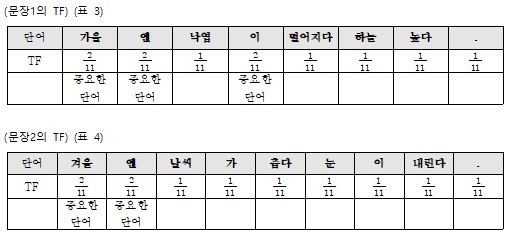
문장1 : 가을엔 낙엽이 떨어지고, 가을엔 하늘이 높다.
문장2 : 겨울엔 날씨가 춥고, 겨울엔 눈이 내린다.
문장1의 총 단어 집합 = {가을,엔, 낙엽,이, 떨어지다, 가을,엔, 하늘,이, 높다,.}
문장2의 총 단어 집합 = {겨울, 엔, 날씨, 가, 춥다, 겨울, 엔, 눈, 이, 내린다,.}
많이 쓰인 단어가 중요하다는 가정으로 보면 표3에서 ‘가을’,‘엔’, ‘이’ 단어가 가장 중요한 단어라 할 수 있고, 표4에서는 ‘겨울’, ‘이’, ‘오다’가 됩니다. 그러나 표3이나 표4에서 조사 ‘이’, ‘엔’은 중요한 단어라고 할 수 없습니다.
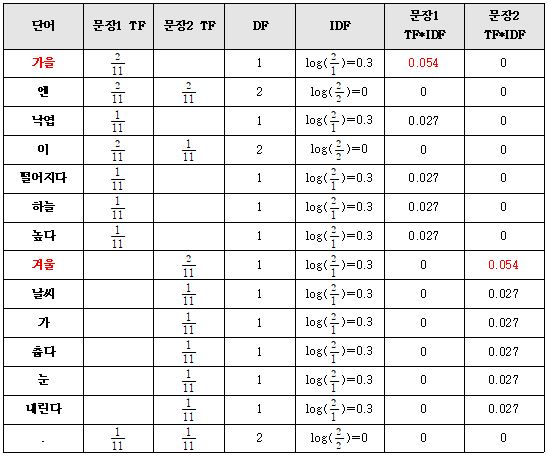
DF(문서빈도, docuemnt frequency)는 특정 단어가 나타난 문서의 수를 뜻합니다.
특정 단어가 문서1, 문서2에만 등장했다면 DF는 2가 됩니다. DF가 클수록 다수 문서에 쓰이는 범용적인 단어라는 것을 알 수 있습니다. TF는 같은 단어라도 문서마다 다른 값을 갖고, DF는 문서가 달라지더라도 단어가 같다면 동일한 값을 갖습니다.
IDF(역문서 빈도, inverse docuemnt frequency)는 중요한 단어를 잘못 예측하는 것을 보완하기 위해 적용합니다. 계산 방법은 전체 문서 수(N)를 해당 단어의 문서빈도(DF)로 나눈 뒤 로그를 취한 값입니다.
참고로, 로그를 사용하지 않고 IDF를 DF의 역수(N/DF)로 사용한다면 총 문서의 수(N)가 커질수록 IDF가 기하급수적으로 커지기 때문에 로그를 사용합니다. 여기서 중요한 것은 ‘IDF값이 클수록 중요한 단어’라는 뜻입니다.
결론적으로 TF-IDF는 다음과 같이 표현할 수 있습니다. TF-IDF는 모든 문서에서 자주 등장하는 단어는 중요도가 낮다고 판단하고, 특정 문서에만 자주 등장하는 단어는 중요도가 높다고 판단합니다. TF-IDF 값이 낮으면 중요도가 낮은 것이고, 값이 높다면 중요도가 크다고 판단할 수 있겠죠?