컴퓨터 과학자들은 머신 러닝에서 더 나아가 기계에도 뇌와 비슷한 구조를 넣어주면 사람처럼 더 똑똑해지지 않을까? 라는 생각에 뇌에 있는 신경세포(뉴런)에 관해 연구하기 시작합니다. 그래서 뉴런과 비슷하게 만든 알고리즘의 이름을 ‘인공신경’이라 부르게 됩니다.
출처
https://mbite.unl.edu/files/papers/2019/j2.pdf
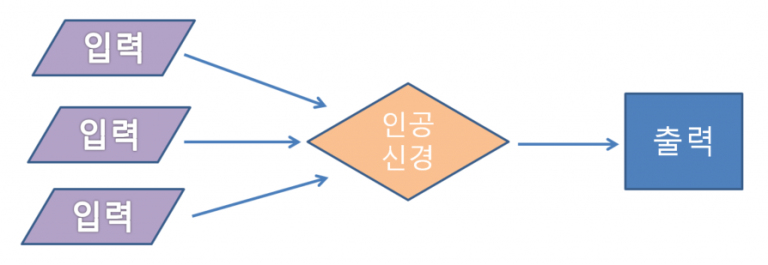
인공신경(Artificial Neural Network)
주변에서 입력받은 데이터를 인공신경이 처리하여 출력값을 다음 인공신경으로 전달합니다.
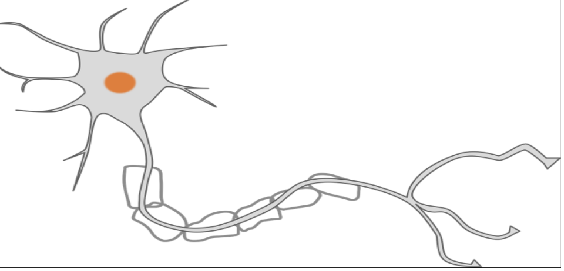
사람의 뇌 신경세포(뉴런)
사람의 뉴런을 보고 인공신경을 만듦
인공신경(Artificial Neural Network)
주변에서 입력받은 데이터를 인공신경이 처리하여 출력값을 다음 인공신경으로 전달합니다.
쉽게 이해하기 위해 경인이라는 학생의 초등학교 생활을 예로 들어 알아봅시다. 초등학생 때 경인이는 학교가 끝나면 집에 가기 전에 항상 군것질거리에 대해 고민을 하곤 했습니다.
1학년
경인이가 1학년 때에는 배고픈 정도가 50이 넘으면 간식을 사 먹고 50을 넘지 않으면 먹지 않고 바로 집으로 갔습니다. 가장 단순했던 시기였습니다.
3학년
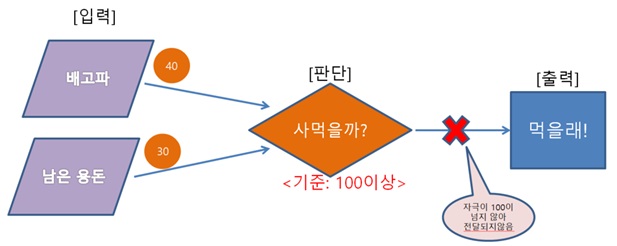
3학년이 된 경인이는 군것질을 살 때 배고픈 정도뿐만 아니라 자신이 가지고 있는 용돈도 고려해야 한다는 것을 깨닫게 되었습니다. 이제 배고픔에 대한 값과 남은 용돈에 대한 값의 합이 100이 넘을 때만 간식을 사 먹기로 결정을 합니다. 이 때 형성된 간단한 인공신경은 사먹는다, 사먹지 않는다 정도의 간단한 의사결정만 하게 됩니다.
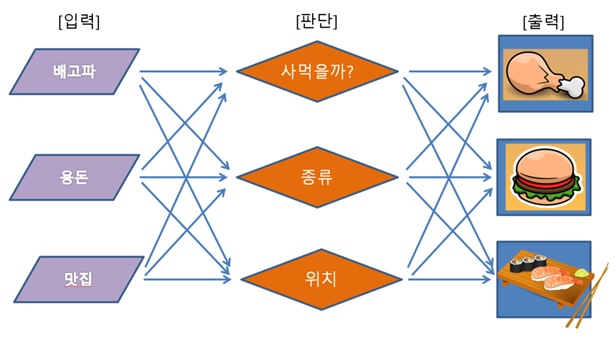
5학년이 된 경인이는 이제 배고픈 정도, 용돈 외에도 맛집이 어디인지도 고려하게 됩니다. 또한, 음식의 종류는 무엇이 좋은지와 같은 고민도 하게 됩니다. 이렇게 선택 기준이 다양해지면서 그에 따라 무엇을 어디서 먹을지에 대한 결정 또한 다양해집니다.
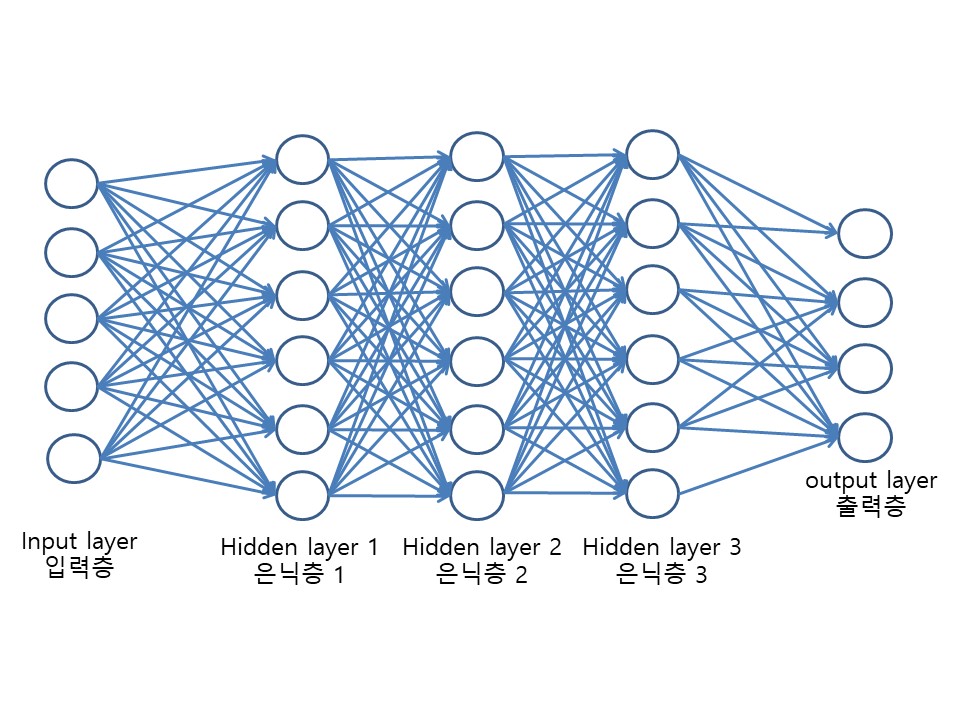
이렇게 결정을 위한 인공신경 여러 개가 모여 한 층을 이루고 그 층들이 여러 층으로 겹겹이 쌓인다고 생각해봅시다. 그렇게 되면 화살표가 무수히 많이 겹쳐 보이면서 그물처럼 복잡해지게 될 것입니다. 이것을 바로 인공신경망(ANN: Artificial Neural Network)이라고 부릅니다. 인공신경망은 복잡할수록 다양한 의사결정을 정확하게 예측할 확률이 높습니다.
2) 인공신경망의 종류
경인이가 아기일 때를 생각해봅시다. 아기일 때는 ‘배고파’, ‘찝찝해’라는 입력 값이 들어오면 ‘울어야지’라는 출력 값이 바로 나옵니다. 또는 ‘엄마다’라는 입력 값이 들어오면 ‘웃어야지’라는 출력 값이 바로 나옵니다. 이렇게 입력층과 출력층으로 이루어진 간단한 구조를 단층신경망(단층 퍼셉트론, Single-Layer Perceptron)이라 합니다.
그리고 경인이가 5학년일 때의 그림을 다시 살펴봅시다. 입력층(배고파, 용돈, 맛집)과 출력층(치킨, 햄버거, 초밥) 사이에 판단하는 층(사먹을까? 종류 위치)이 있습니다. 이러한 층을 은닉층hidden layer)라고 합니다. 이러한 은닉층이 존재하는 구조를 다층 신경망(다층 퍼셉트론, Multi-Layer Perceptron)이라고 합니다.
Non-deep feedforward neural network
쉘로우 러닝(Shallow learning)학습 환경
Deep neural network
딥 러닝(Deep learning)학습 환경
출처: 파워포인트로 제작
다층 신경망은 위에 보이는 표에서 알 수 있듯 얕은 신경망과 심층 신경망으로 나뉩니다.
5학년 때 그림에서 [판단] 부분을 살펴보면 ’사먹을까?‘, ’종류‘, ’위치‘가 한 세트처럼 생각됩니다. 이러한 세트의 판단층을 은닉층(hidden layer)이라고 합니다. 은닉층이 1개 일때는 얕은 신경망(Non-deep feedforward neural network)이라고 하며, 얕은 신경망에서는 기계가 쉘로우 러닝(Shallow learning)이라고 말하는 얕은 수준의 학습만 할 수 있습니다. 처음 인공신경망이 만들어질 때는 기술수준이 낮아서 층을 여러 겹으로 쌓을 수 없었기 때문에 이러한 학습 방법이 이루어질 수밖에 없었습니다.
최근에는 기술이 발전하면서 은닉층을 여러층으로 쌓을 수 있게 되면서 심층신경망(Deep neural network)을 만들 수 있게 되었습니다. 그리고 이러한 심층신경망에서 일어나는 학습을 딥 러닝(Deep learning) 이라고 합니다.
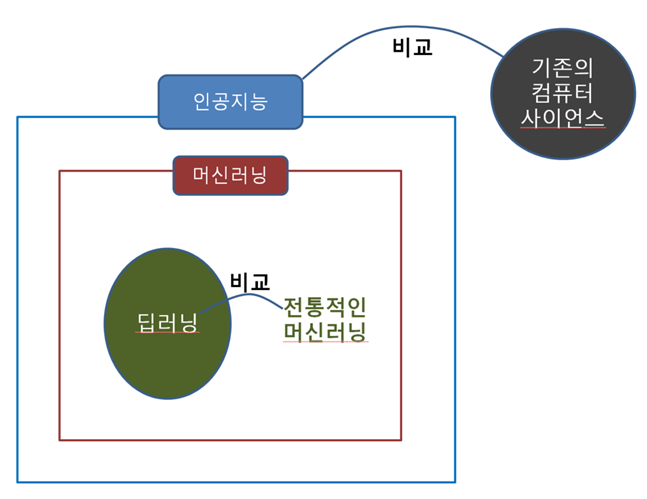
3) 인공지능, 머신러닝, 딥러닝의 관계
출처: 파워포인트로 제작
위의 그림에서 알 수 있듯 인공지능>머신러닝>딥러닝의 관계는 식물>꽃>장미꽃의 관계라고 생각하면 쉽습니다. 인공지능이라는 큰 범위 안에 머신러닝이라는 방법이 있고, 머신러닝을 구현해내는 다양한 방법 중 하나가 딥러닝입니다. 인공지능은 기계가 인간의 지능을 모방해 인간과 비슷하게 움직이도록 만든 모든 기술을 뜻합니다. 그 중 머신 러닝은 사람이 경험을 통해 지식을 습득하는 것처럼 사람의 학습방법을 모방해 학습하는 것으로 다양한 데이터들을 탐색함으로써 데이터 간의 관계를 파악합니다.
딥러닝은 이러한 머신 러닝의 여러 학습 방법 중 하나이므로 머신 러닝이 무엇이었는지 생각하는 것부터 시작해봅시다. 사람의 학습은 뇌에서 이루어집니다. 그러니까 기계에도 뇌와 비슷한 구조를 만들어주어야겠다는 생각에서 출발한 것입니다. 그 출발점이 앞에서 설명한 인공신경이였고, 그 인공신경들이 서로 연결되어 그물처럼 얽힌 것이 인공신경망이였으며, 그 인공신경망의 구조 중 핵심구조인 층(은닉층)이 여러 개로 쌓여 있는 DNN이 있는데, 그 DNN을 활용하여 학습하는 방법이 딥러닝입니다. 그리고 이러한 딥러닝을 활용해 이미지인식, 음성인식, 자율주행자동차, 신약개발, 질병진단 프로그램을 개발하고 있습니다.
머신러닝을 이해하기 위해 기존의 컴퓨터 사이언스와 비교해봅시다. 기존 컴퓨터 사이언스에서 활용한 방법은 1이라는 값, 2라는 값 그리고 +라는 알고리즘을 주고 그 결과값을 얻어내는 방식이었습니다. 마치 지금의 계산기와 비슷합니다.
하지만 머신 러닝은 1이라는 값과 2라는 값 그리고 결과값 3을 주고 그 관계에 대해 알아내도록 합니다. 그럼 어떻게 이 숫자들의 관계가 +(더하기)라는 것을 알 수 있을까요? 이는 많은 데이터를 주면 가능합니다. (1,2와 3), (2,3과 5), (3,4와 7) … 이와 같은 데이터를 수백만, 수천만개를 주면 머신 러닝을 통해 ‘아 이 관계는 +(더하기)로 이루어졌구나.’ 스스로 파악하게 됩니다. 그래서 머신러닝에서는 많은 데이터 즉, 빅데이터를 줄수록 더 정확한 알고리즘을 사람에게 알려줄 수 있습니다.
이렇게 보면 머신 러닝과 딥러닝은 기본적으로 비교할 수 없는 관계입니다. 왜냐하면, 이것은 꽃과 장미처럼 한쪽이 의미상 다른 쪽을 포함하는 상하 관계이기 때문입니다. 장미와 튤립은 비교할 수 있지만, 꽃과 장미는 비교할 수 없습니다. 그래서 딥러닝과 머신 러닝을 비교할 때에는 ‘딥러닝’과 ‘딥러닝이 아닌 전통적인 머신 러닝’을 비교해야 합니다.
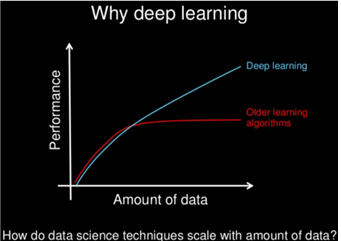
위 그래프에서 파란색은 딥러닝, 빨간색은 전통적인 머신 러닝을 나타냅니다. X축은 ‘데이터의 양’이고 Y축은 ‘성능’입니다. 그래프를 해석해보면 데이터의 양이 적을 때에는 전통적인 머신 러닝의 성능이 좋지만 데이터의 양이 많아질수록 머신 러닝의 성능은 일정해지는 반면 딥러닝의 성능은 계속 좋아진다는 것을 확인할 수 있습니다. 이는 빅데이터를 가지고 있을 때는 딥러닝이 유리하고, 비교적 내가 가진 데이터의 양이 적을 때에는 머신 러닝이 유리하다는 뜻입니다.
더불어 딥러닝은 빅데이터를 가졌을 때 성능이 좋아지므로 고 사양의 하드웨어가 필요합니다.(일반적인 CPU, 병렬처리를 할 수 있는 GPU, 그 이상 뛰어난 TPU와 같은 하드웨어) 참고로 이세돌 9단과 대결해 유명해진 알파고는 1920개의 CPU와 280개의 GPU로 학습시킨 프로그램입니다. 그리고 학습 시간 측면에서 볼 때, 적은 데이터를 처리하는 전통적인 머신 러닝은 몇 초에서 몇시간 정도의 비교적 짧은 시간이 걸리는 반면, 빅데이터를 처리하는 딥러닝은 며칠에서 길면 몇 주 정도의 많은 시간이 걸린다는 차이가 있습니다.
4) 딥러닝의 사례
AR콘텐츠
딥러닝 기법이 적용된 증강현실은 카메라를 통해 보이는 모든 사물과 AR오브젝트를 분리하여 다른 레이어에 넣습니다. 그러면 사람들사이에 오브젝트를 넣거나 사람을 AR 오브젝트사이에 존재하도록 하는 기술(People occlusion)을 구현할 수 있습니다.
얼굴을 인식하기 위해서 입력된 수많은 이미지를 많은 조각으로 나눕니다. 그리고 각각의 조각에 이미지 필터를 적용하여 이미지를 단순화(convolution)시키고, 변형(acrivation)과 샘플링(pooling)이라는 과정을 거치도록 합니다. 이러한 과정을 여러 번 반복하여 마지막에 예측할 수 있도록 하는 것이 얼굴 인식에 들어간 딥러닝 중 CNN 기술입니다.
처음 객체 인식이 개발되었을 때에는 하나의 사진 속에 존재하는 이미지 하나를 처리하는 데 20초가 걸렸습니다. 하지만 지금은 그 시간이 1/500초로 빨라지고 하나의 이미지 속에 존재하는 여러 객체 즉 사람이나 사물들을 동시에 인식할 수 있는 정도까지 발전했습니다. 이를 사물 감지의 ‘욜로’법(You Only Look Once)이라 부르기도 합니다.
사물인식 이미지 출처
https://europepmc.org/article/pmc/pmc6727496
무인 항공기
무인 항공기가 연구되는 분야 중에는 조난자를 자동으로 탐지하는 딥러닝 기반 시각 인식 모델이 있습니다. 이는 드론이 해변을 날아다니면서 물에 빠진 사람을 찾아 자동으로 119에 신고를 합니다.